数据压缩是一项复杂的任务,因为图像或视频的每一帧都必须经过技术处理,并且在通过网络发送之前不能影响原始数据的质量。视频格式的两种压缩方式可分为帧间压缩和帧内压缩,本文将讨论这两种压缩方式的特点和工作原理及其区别。
帧间压缩
这是一种跨视频帧的压缩技术,帧与帧之间会有细微的变化。由于使用参考帧检查帧,并且只记录或存储差异,因此存储的数据较少。在编码过程中,会分析一个输入帧并选择关键帧进行压缩,并将此关键帧用作其余帧的参考。在解压缩时,我们需要通过比较关键帧来添加帧中发生的变化。每当视频发生重大变化(与现有场景无关的新场景)时,就会更新这些关键帧。
请看一个实时示例: 主播在某频道上播报现场新闻,此时只有主播的身体在移动,背景帧中没有变化。因此,要存储的差异只是人的动作,而不是每一帧的背景。与第一帧的差异被视为关键帧,并用作其余帧的参考。
帧分为三种类型,常用于视频压缩算法:
- I 帧:它被称为帧内编码帧,是解码过程中用作参考的实际关键帧。它包含解码所需的所有信息。它为每个场景提供轮廓,从而减少编码帧所需的位数。
- P 帧:预测帧使用 I 帧作为参考帧来预测参考和剩余帧的内容之间的差异。
- B 帧:它预测 I 帧和 p 帧中可用的信息以供参考,称为双向帧。
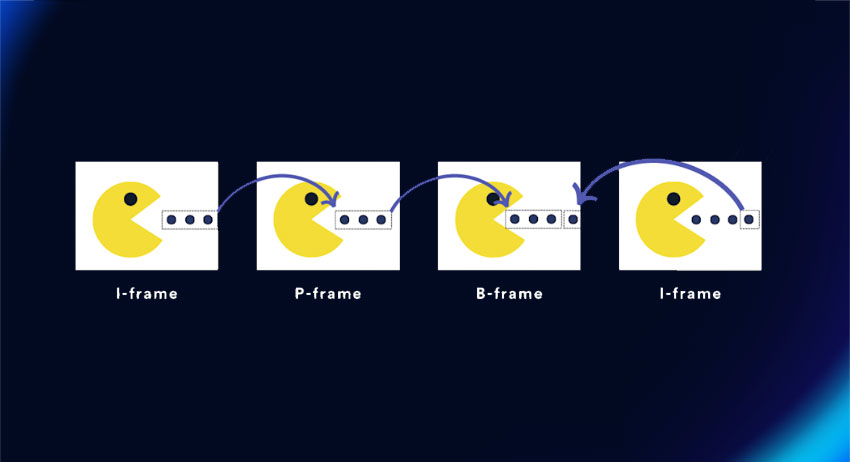

另外还有S 帧:此切换帧是一种预测帧,使用 I 帧作为参考,其余信息从视频流中获取。它是作为 AV1 代码的一部分发明的,允许自适应比特率,在不降低视频质量的情况下传输较小部分的帧。
帧内压缩
压缩过程在帧内进行。单个图像帧被分成多个块,记录每个像素之间的差异并对其进行编码。无损和有损压缩针对与单个或当前帧相关的信息,并且得出的差异或预测与输入视频序列中的其他帧无关或不进行比较。
视频序列中的每个图片都单独编码为单个帧。假设我们正在使用运动联合图像专家组压缩视频,该技术将帧压缩为单个图像。用户可以重新创建每个帧,而无需从前一个和即将到来的帧中获取信息。这在编辑视频时很有用,因为每个帧都在序列中编码以减小大小并降低比特率,同时不影响原始视频的质量。
帧间压缩和帧内压缩之间的差异
| 差异类别 | 帧内压缩 | 帧间压缩 |
|---|---|---|
| 定义 | 压缩过程是在可用帧上进行的。 | 对视频序列的每一帧进行压缩。 |
| 功能 | 它能识别一帧上的关键帧并将其用作其余帧的参考。 | 它不依赖于先前的信息来处理当前帧。 |
| 冗余 | 连续帧之间的时间冗余被打破。 | 帧内的空间冗余。 |
| 处理时间 | 由于算法需要处理和压缩多帧才能进行解码,因此需要较长的处理时间。 | 由于编码发生在各个帧内,因此时间比帧内编码要少。 |
| 依赖 | 它依赖于 i 帧或 p 帧的关键帧来了解差异并进行计算。 | 它不依赖关键帧来了解像素内的差异。 |
| 类型 | I 帧、B 帧、P 帧和 S 帧 | P 帧和 B 帧。 |
| 一些编解码器 | MPEG-2、MPEG-4、H.265、H.264 | DVCProHD、Apple ProRes 和 Avid DNxHD。 |
结论
视频压缩方法旨在减小视频大小,保持与原始输入视频相同的质量,从而加快传输速度并节省存储空间。各种编解码器方法都用于无损和有损、帧间和帧内压缩。视频专业人员可以根据其使用的软件以及在相同或不同的背景环境中如何按顺序捕获帧来使用帧间或帧内压缩。
原创文章,作者:ZEGO即构科技,如若转载,请注明出处:https://market-blogs.zego.im/reports-baike/2026/