

过去一年间,语音 AI 领域发生了翻天覆地的变化,为开发者提供了多种独特的架构方案,每种方案都各有优劣。从传统管道的可靠性到原生Speech-to-Speech模型的对话自然度,选择合适的架构将决定语音应用的成败。
本文介绍了三种不同的模式:
- 传统管道架构:语音转文本(STT)→ 大语言模型(LLM)→ 文本转语音(TTS),在需要可靠性和工具集成的企业应用中占主导地位。
- Speech-to-Speech 模型:在对话应用中表现卓越。在这些场景中,自然流畅的对话体验远比复杂推理更具价值。
- 混合方案(如半级联架构或 supervisor 架构):逐渐成为中期复杂实际部署的最佳平衡方案。
在本文的其它部分,为简化说明,我们将忽略架构中某些重要组件,例如回合结束检测、噪声抑制或VAD/中断检测,而专注于音频输入如何被处理以生成音频输出的过程。
传统管道:生产主力
2025年,STT→LLM→TTS 模式仍驱动着绝大多数商业语音 AI 部署,从每月处理数千个呼叫的客服中心到管理患者交互的医疗系统。这种模块化架构通过连续的阶段处理语音:语音识别将音频转为文本,语言模型生成响应,文本转语音技术最终生成输出音频。

延迟特性仍是主要挑战,端到端响应时间通常在 500 毫秒至 1000 毫秒之间。不过,流式传输优化现在可在边缘部署时实现低于 300 毫秒的性能。
专业的 TTS 模型能够以极少的样本提供多种语音和语音检索,并通过自然语言提示控制风格,从而实现卓越的自然语音质量。语音合成与语言处理的分离,允许独立优化语音特性。
灵活性是该架构的最大优势,开发者可以自由切换组件。在 STT 方面,可以选择 Whisper、Deepgram 或 AssemblyAI;在推理方面,可以选择 GPT-4o、Claude 或 Gemini;并针对特定用例优化 TTS。 这种模块化设计支持特定领域定制化,从医学术语精准度到品牌专属语音个性均可实现。
工具调用能力依然无可匹敌,基于文本的 LLM 可实现原生函数调用、无缝 API 集成及复杂工作流自动化。该架构在客户关系管理(CRM)集成、实时数据检索以及需要可靠工具执行的多步骤业务流程方面表现卓越。
对话上下文可通过高度可控的方式扩展处理,在控制成本的前提下,为长会话应用压缩、摘要生成及上下文窗口等技术。
该方案最适用于企业级应用场景,尤其适合追求可靠性而非绝对最低延迟、需要复杂工具集成,以及需灵活优化单个组件的场景。
这种方法的另一个好处是,管道的不同步骤可以在不同的地方执行,例如在设备上运行 STT 阶段以获得最高的质量和性能,在云端运行管道的其余部分以获得最大的灵活性和质量。
多模态 Speech-to-Speech 架构:卓越的对话体验
像 OpenAI 的 Realtime API 和 Google 的 Gemini Live 这样的原生 Speech-to-Speech 模型代表着对话式 AI 的前沿技术,它们无需文本中介即可直接处理音频。这些系统显著降低了延迟——响应时间通常为 200-600 毫秒,同时保留了基于文本的系统不可避免地会丢失的情感语境和对话流程。

延迟特性比传统管道提升了 2 到 5 倍。OpenAI 的 Realtime API 可在 600 毫秒内提供流式响应, 而 Google 的原生音频模型也能达到类似的性能。省去了多次 API 调用和文本转换步骤,消除了累积延迟,从而实现了真正的实时对话。
通过在对话数据上进行端到端训练的模型,自然语音质量达到全新高度。Google 原生模型支持情感对话响应情绪表达、主动音频识别区分直接对话与背景交谈,以及无缝多语言切换。
与传统流程相比,灵活性仍然受到限制。语音定制仅限于预设选项,切换不同模型供应商需进行架构变更。但两大平台均提供超越传统方案的全面对话管理、会话持久化及中断处理能力。
工具调用能力表现参差不齐,这是该模型最大的局限性之一,也促使本文后续介绍了两种架构(supervisor architecture 与半级联模型)。
对话上下文更为有限,通常会话时长上限较短。
此类模型在以下对话场景中表现卓越:语言学习应用、语音控制界面、需情感智能的客服系统及无障碍应用。这些场景更注重自然对话流而非复杂推理。该技术尤其适用于优先考虑用户体验而非企业工具集成的消费级应用。
Supervisor 模型:智能任务分派
Supervisor architecture(监督架构)作为一种混合方案应运而生,它利用快速 Speech-to-Speech 模型处理对话流程,同时将复杂任务分派给强大的文本的 LLM。OpenAI在其示例应用中展示了这种“聊天-监督”模式,实现了对话自然度与高级推理能力的平衡。
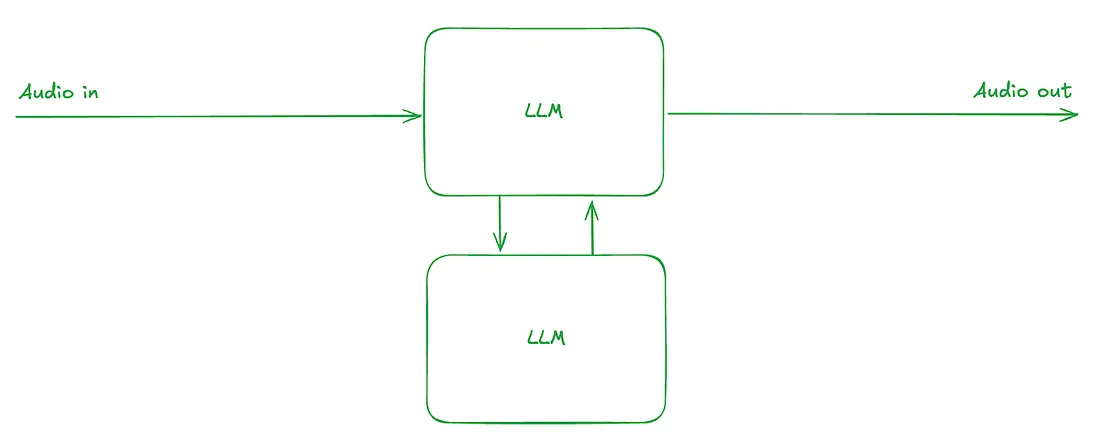
延迟特性显示基础交互可实现即时响应(200-500毫秒),当需要 supervisor 介入时则额外增加1.5-3秒延迟。该方案在保持即时确认以维持自然对话流的同时,显著优于传统管道架构。
通过统一的 TTS 处理和精心的上下文保存,自然的语音质量可确保跨授权范围的一致性。聊天代理在 supervisor 处理过程中提供自然的填充短语,确保在后台执行复杂任务的同时保持对话的流畅性。
灵活性体现在可配置的任务路由逻辑、可定制的决策边界和多模态功能上。系统可以根据置信度阈值、任务复杂性或领域专业知识要求进行路由。
工具调用能力是其关键优势之一,它通过专门的模型选择增强了可靠性,并通过监督推理实现了更佳的错误处理。复杂的工具链、并行执行和上下文感知的工具选择在成功率和可靠性方面均超越了单一模型方法。
当需要可靠的工具调用但不能牺牲自然对话和延迟时,supervisor 模式被证明是最佳的。
半级联模型:生产优化的可靠性
半级联(Half-cascade)架构将原生音频输入处理与传统文本转语音输出相结合,实现了性能与生产可靠性之间的战略平衡。该方案由 Google Live Gemini API 提供,也可通过其他服务商实现。此方法在保持音频理解优势的同时,充分利用了成熟的 TTS 基础设施。

延迟特性实现具有竞争力的 500-800 毫秒响应时间,比传统管道快20-40%,同时保持生产可靠性。
自然语音质量提供 8 种专业语音,涵盖 24 种语言,且性能一致,但情感表现力不及原生音频模型。可预测的 TTS 输出支持质量保证与合规性,同时提供精细的语音参数控制。
灵活性通过确定性输出、强大的错误处理和可扩展的 TTS 基础设施,为生产环境带来显著优势。该架构可轻松集成至传统系统,支持文本与音频同步输出,并实现语音品牌定制与个性化配置。
工具调用功能远超原生音频方案,Google 专门设计了半级联模型,以实现卓越的函数调用性能。异步工具执行、强大的错误恢复能力以及优化的复杂工作流程,使该架构成为工具密集型应用的理想之选。
当需要可靠的工具调用但链式架构太慢或不能提供足够真实的对话时,半级联架构被证明是最佳的。
总结:架构选择
当可靠性和工具集成至关重要时,选择传统管道:企业客户服务、复杂的业务工作流程、需要组件级优化的应用程序以及要求审计跟踪的监管环境。
为优先考虑自然性的对话应用选择 Speech-to-Speech 模型:语言学习、语音助手、情感应用和用户体验胜过复杂推理的消费产品。
如果无法同时牺牲自然对话和可靠的工具调用,请选择混合方法(supervisor 架构或半级联架构)。如果使用 Gemini Live,半级联方法尤其适用,因为它不需要更改代码,而 supervisor 架构方法更容易应用于任何模型提供商。
作者:Gustavo Garcia
译自:https://medium.com/@ggarciabernardo/voice-ai-architectures-from-traditional-pipelines-to-speech-to-speech-and-hybrid-approaches-645b671d41ec
ZEGO 实时互动 AI Agent,全面优化互动架构,可快速实现用户与 AI(智能体)进行超低延迟的 IM 图文聊天、语音通话、数字人语音通话等互动能力。点击注册轻松打造多模态语音 AI Agent。
原创文章,作者:ZEGO即构科技,如若转载,请注明出处:https://market-blogs.zego.im/reports-technique/2720/