

从语音识别到多模态工具,音频领域 AI 的兴起凸显了一点:强大的数据预处理至关重要。其中关键步骤之一便是采样率转换(SRC)。如果输入 44.1 kHz 源的数据,以 16 kHz 采样率的音频训练的 AI 模型将无法获得良好的结果,因为它学习识别的频谱模式会发生根本性改变。
重采样是指将数字音频信号从一种采样率转换为另一种采样率的过程。这项任务乍看似乎简单,实则可能成为音频处理管道(pipeline)性能及模型精度的瓶颈。这是数字信号处理中的一项挑战,它要求我们理解音频保真度、计算成本与延迟之间的权衡关系。
奈奎斯特定理与混叠现象
奈奎斯特-香农采样定理指出:要完美地将连续信号以数字形式呈现,采样频率必须大于信号中最高频率的两倍。下采样时,很容易违反此条件。如果将包含高频成分的信号抽取到较低的采样率,这些高频成分不会简单地消失。相反,它们会“折返”到较低的频率范围,从而产生一种不可逆的失真,即混叠。对于 AI 模型,例如自动语音识别 (ASR) 系统,混叠会破坏其所依赖的语音模式,从而降低准确性并增加错误率。
插值
重采样的主要目标是精确确定原始样本之间的时间点的波值。这个过程称为插值。
理论上完美的方法是正弦插值。该策略受奈奎斯特-香农采样定理的约束,假设信号带宽被适当限制,则可以从样本中完美地重建原始连续信号。
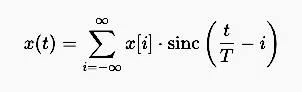
这里,连续波 x(t) 在任意时刻 t 的值是所有原始样本 x[i] 的加权和。sinc函数为每个样本提供了精确的理想权重。在时域中,应用此公式相当于施加一个“brick-wall”低通滤波器,它具有完全平坦的通带和无限陡峭的截止频率。
窗口函数
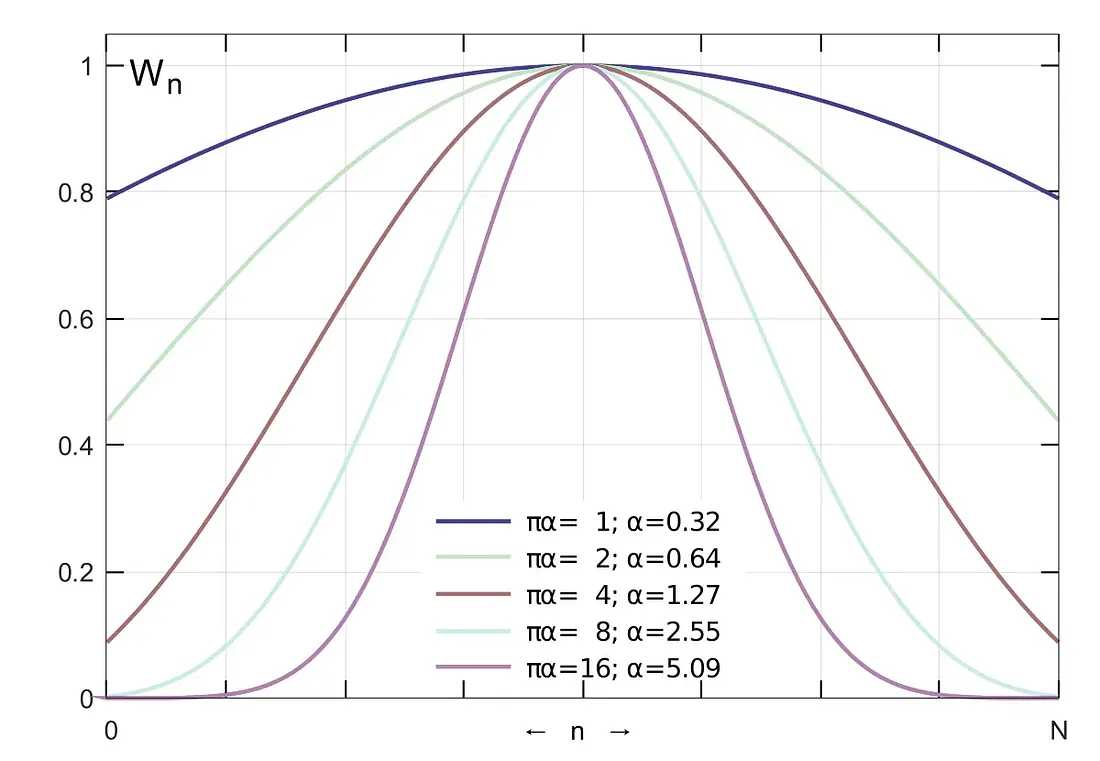
理想的 sinc 插值滤波器具有无限长度。为使用它,我们必须将其截断为有限长度(例如 64 或 128 个“taps”)。
若直接截断滤波器(使用“矩形窗口”),会产生尖锐的不连续性或“抖动”,在频域中表现为明显的纹波和伪影。
截断型 sinc 滤波器应用了一个窗口函数。这种渐变函数能使滤波器系数在边缘平滑归零,类似于“淡出”效果。此举虽能抑制多余纹波,但会导致滤波器截止频率略微降低(过渡带变宽)。凯塞窗是一种常见且高度灵活的选择,因为它可以精确调整这种权衡,但还有很多其他的选择,例如 Hann、Hamming 等。
滤波器设计挑战
如前所述,重采样是通过将信号与 sinc 函数进行卷积来实现的,而 sinc 函数则由数字滤波器进行近似。根据所选的滤波器类型,这将在以下几个方面引入关键的工程权衡:
- 过渡带宽:滤波器截止的锐度。
- 阻带衰减:不需要的频率被拒绝的程度。
- 相位响应:应用于不同频率的时间延迟量。
重采样器的质量最终衡量的是其内部过滤器如何管理这些权衡。
有限冲激响应(FIR)
FIR 滤波器是非递归的,这意味着其输出仅为有限个输入样本的加权和。其控制方程为直接卷积:

其中y[n]是输出,x[n]是输入,h[k]是滤波器系数(脉冲响应),N是滤波器阶数或“taps”数。
- 优点:它们可以设计成具有完美的线性相位响应,通过均匀延迟所有频率来保持波形的时域形态。这对于音频来说非常理想。
- 缺点:实现陡峭的频率截止需要采用高阶(长)的滤波器,这可能导致计算成本高昂。
无限冲激响应(IIR)
IIR 滤波器具有递归特性,通过反馈机制使输出同时依赖于先前输入与先前输出。其差分方程为:
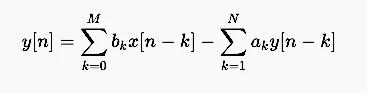
其中 bk 为前馈系数,ak 为反馈系数。
- 优点:其计算效率极高,能实现比同阶 FIR 滤波器更陡峭的截止特性。
- 缺点:反馈机制导致非线性相位响应,可能引起相位失真。若设计不当,还存在不稳定风险。
阐明这些核心概念后,我们将继续探讨重采样过程的不同实现方法。
多相 FIR
该方法是高质量离线重采样领域的行业标准,也是 FFmpeg 等强大工具的核心算法。它通过单个高阶 FIR 滤波器,对 sinc 滤波器进行直接且稳健的近似。
此方法的主要挑战在于超长 FIR 滤波器的计算成本。初级实现方案效率低下,因其涉及大量零乘法运算。解决方案是一种优雅的结构优化技术,称位多相分解。
多相技术并非实现一个庞大而缓慢的滤波器,而是将其分解为一组更小、更快的子滤波器(或“相位”)。对于给定的输出样本,仅激活必要的子滤波器。这在数学上与原始滤波器等效,但显著减少了所需的计算量,使高质量的 FIR 滤波在计算上易于处理。
由于该算法基于直接卷积,因此它本质上易于并行处理,并且非常适合 GPU 加速。这种结构也适用于 PyTorch 等深度学习框架,允许重采样成为模型计算图的可微分部分。稍后将详细介绍。
两级混合 IIR+FIR
该算法体现了一种“分而治之”的策略,其设计初衷是最大化计算效率并最小化延迟,尤其是在实时或资源受限的环境中。它通过协同结合两种滤波器拓扑来实现这一点。
- 第一阶段:IIR 滤波器。初始的高效 IIR 滤波器执行粗略的重采样步骤(通常是使用半带滤波器进行简单的 2 倍抽取或插值)。IIR 滤波器的作用是以极低的数学运算次数提供非常尖锐、有效的抗混叠截止频率。
- 第二阶段:FIR 滤波器。IIR阶段之后是第二个更短的 FIR 滤波器。由于 IIR 滤波器已经完成了抗混叠任务中最困难的部分,因此该 FIR 滤波器的阶数可以低得多。其主要作用是通过清理滤波器的过渡带来“抛光”信号,并且至关重要的是,补偿 IIR 阶段引入的相位失真,从而形成一个具有近线性相位响应的复合系统。
通过战略性地分工协作,使用 IIR 滤波器提升效率,同时借助 FIR 滤波器确保保真度与相位校正。这种混合模型能够实现与长单级 FIR 滤波器相当的质量,同时显著减少计算量。这使其成为低延迟 CPU 应用的理想选择。
可微分 FIR
可微分性背后的原理非常深刻。它允许损失函数的梯度通过重采样器反向传播,从而可能使其成为模型计算图的一部分。这有几个优点:
- 端到端学习:重采样滤波器的参数理论上可以变得可学习,从而允许模型优化其自身的输入处理。
- GPU 加速:操作与模型一起在 GPU 上执行,加速训练期间大数据批次的处理并防止 CPU 瓶颈。
- 简化管道:它消除了对外部依赖的需求,允许在单一框架内处理数据。
算法基础与高保真窗口 sinc 插值相同,但创新之处在于其实现。该操作被设计为 1D convolution(一维卷积)。这种结构实质上是对多相 FIR 滤波器的直接实现。该算法预先计算一组滤波器核(即多相分量),并通过 PyTorch 的 F.conv1d 函数配合特定步长实现高效应用。
此设计充分利用 GPU 并行处理能力,实现高吞吐量重采样,特别适用于模型训练过程中的批量处理场景。
结论
重采样范式的正确选择是工程权衡的结果。不存在唯一的“最佳”算法;最优选择取决于应用场景的具体约束条件。复杂的语音 AI 管道可能在不同阶段采用不同策略:使用多相 FIR 滤波器进行初始数据集规范化,使用可微分 FIR 进行训练期间的动态增强,以及使用自定义混合滤波器进行低延迟部署。理解这些方法间的权衡关系,有助于开发者做出明智决策,确保模型建立在高保真、高效处理的音频数据基础上。
作者:Filter Cutter
原文:https://medium.com/@filtercutter/audio-resampling-in-voice-ai-pipelines-8188ead4ccc4
共建实时互动世界
立即使用实时音视频和聊天 SDK 构建应用程序!
原创文章,作者:ZEGO即构科技,如若转载,请注明出处:https://market-blogs.zego.im/reports-technique/2743/