超分辨率(Super Resolution,SR)是从给定的低分辨率(Low Resolution, LR)图像中恢复高分辨率(High Resolution,HR)图像的过程,是计算机视觉的一个经典应用。SR 是指通过软件或硬件的方法,从观测到的低分辨率图像重建出相应的高分辨率图像。在直播、点播、监控设备、视频编解码、卫星图像遥感、数字高清、显微成像、视频复原和医学影像等领域都有重要的应用价值。
超分辨率在广义上包含三种技术方向:
1)单帧图像超分辨率放大;
2)多帧连续图像重建超分辨率单帧图像;
3)视频序列的超分辨率重建视频帧。
移动端超分面临的挑战
业界主流基于深度学习的超分模型参数量在 300K 以上,FLOPs 在 100G 以上,在普通 GPU 显卡上,都很难做到 30 帧每秒(640×360 放大2倍到 1280×720),在移动端上只能处理单帧图片,且不能用于实时通话中。
所以,如何让超分在移动端实时跑起来,将是个巨大的挑战:
1、移动端实时视频分辨率比较低(640×480 左右),而移动手机显示屏分辨率一般都比较高(1920×1080,甚至到 2340×1080),如 Apple 13 ProMax 显示屏分辨率为 2778 x 1284;
2、每帧处理耗时要低于30毫秒(640×360 超分到 1280×720),否则会有明显的卡顿;
3、超分处理后,图像或视频相对于没开启超分,要有明显的主观、客观质量提升。
那么,基于深度学习的超分网络模型设计也需要面临挑战:
挑战一:网络模型参数量过大,一般都大于 500K;
挑战二:模型运算量过大,推理时非常慢,一般都大于 100G FLOPs;
挑战三:超分区别于其他计算机视觉如目标检测与跟踪技术,不能对输入的图像或视频进行缩小。
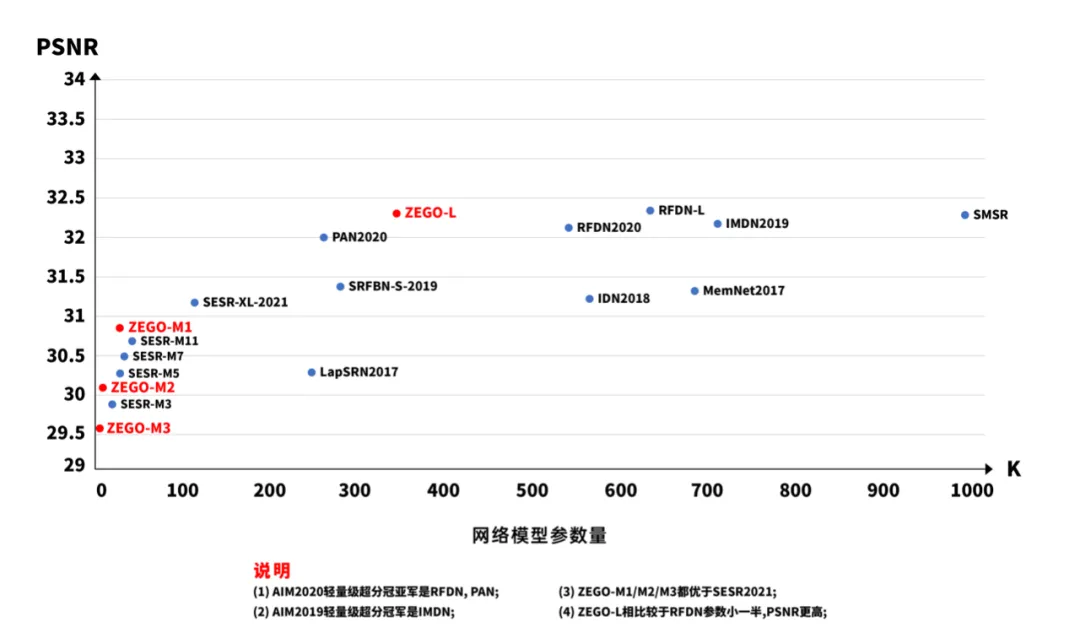

通过图1我们可以看到,即构的超分技术,无论是轻量级模型,还是极小轻量级模型,客观数据表现都不俗,并且在即构的产品应用中,能覆盖 Android 和 iOS 手机 2500+ 款机型。 那么,即构在面对上述问题时是如何解决的呢?
即构超分技术
经实测,近十年公开报道的超分技术无一能在移动端实时通话中运行起来,更不能谈及覆盖更广的移动端机型,而业界最低运算量(PAN2020[4])的超分模型,也很难实时跑起来,使得机型覆盖率极度有限,某友商超分任务覆盖不足 50 款指定高端旗舰机型,而某大厂基于谷歌 RAISR 方法优化的效果不足以保证。
图1中的 IMDN2019([1]) 是 AIM2019 Challenge on Efficient Super-Resolution 比赛冠军,RFDN2020([5]) 和 PAN2020([4])则分别是 AIM2020 冠军和亚军,也仅仅能在 NVIDIA GeForce 1080ti 显卡上实时跑,移动端不能奢想。
为了解决这个问题,我们需要一些原则来指导模型的设计,主要从以下三个方面思考:
1、指导模型设计:什么样的模型才是最好的候选网络模型,以减少训练次数;
2、极轻量级模型设计:在适配移动端设备时,主客观效果相对于大模型不显著下降,且显著优于传统插值放大算法;
3、模型量化压缩及加速,及工程化。
2.1 指导模型设计
考虑到 GPU 资源有限、任务多,所以要尽可能的设计一个直达任务目标的极小网络模型,且节约 GPU 资源。
北京某超算中心提供的 2 卡 V100-32G 云服务,每小时 6 元,则一个月的费用是7x24x30x6元=30240元/月。所以当我们设计了一个模型,花了很长时间好不容易训练出来,结果在移动端没法实时,也是浪费算力和人力。
那么我们如何能在不做任何训练的情况下,从仅有的一些模型数据中,寻找真正所需要的移动端网络模型呢?
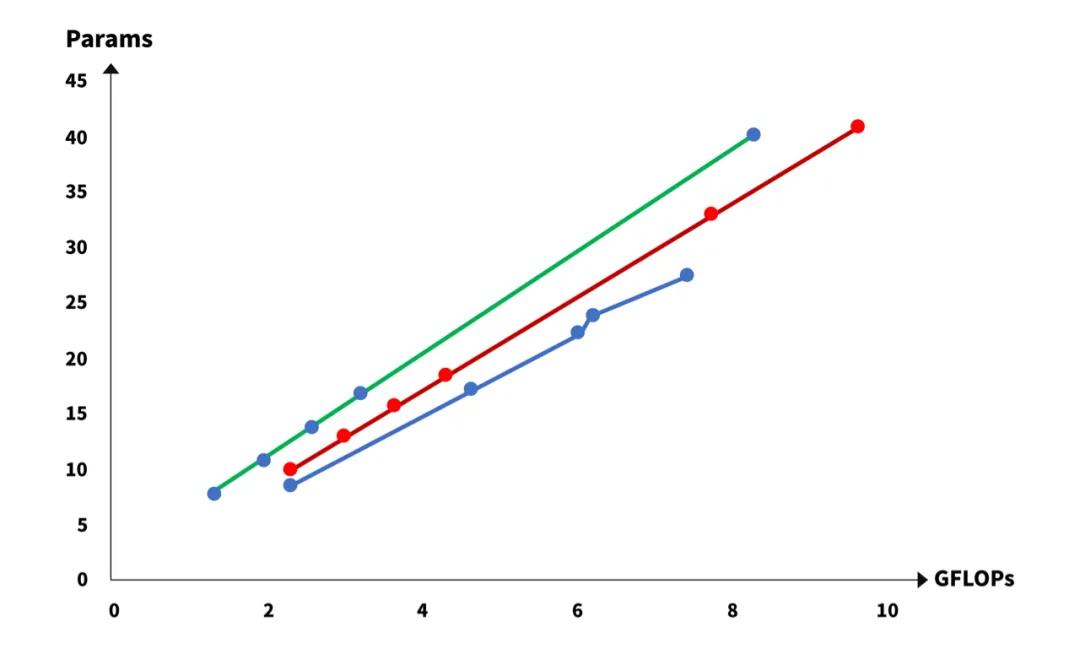
图2中,不同颜色的曲线表示不同架构下的超分模型,曲线上的点则表示不同深度和宽度的模型参数量和运算量。实际设计模型,还需要加入更多维度,如输入图像的宽高、特征图的通道数等。
那么是不是可以总结为我们要去寻找 Params 大,而 FLOPs 小的网络模型?
Params 大则网络模型表现力强, FLOPs 小则运行速度快(不一定准确,依赖于推理库,若模型中操作算子是常规的操作算子,则大概率是正确的)。若上面推断正确,则上述图2表明:绿色代表的超分模型强于红色,也强于蓝色,那么,我们就需要设计出越来越陡的曲线模型。对每种设计的模型,训练一个epoch,然后移植到移动端测试实际性能,而“抖“的上确界在哪里,就需要实验数据来支撑。
这就给了我们一个设计网络模型的指导方向:参数量尽可能的多,而运算量尽可能的少,并结合实测数据,探测较优的、可能实时的候选模型。
依据这样的原则,我们就能够对所设计的网络模型选择一个合理的方向,然后基于选定的方向,找到适合在移动端实时运行的模型的深度和宽度等参数。
另外,算法选型也是一种考验,开源的超分足够多,但落地产品化的极少,产业界不乏大厂采用如下方案:
1)基于 RAISR(Google,2016) 本质就是一般传统的基于机器学习的哈希算法,根据低分辨率图像块里的内容和几何特征对其进行分类,最后利用机器学习算法,学习低分辨率图像块和高分辨率图像块之间的关系,得出重建矩阵,基于 RAISR 进行裁剪优化,效果得不到保证。
2)基于 SRGAN (Christian Ledi, 2016)以及变种方法进行优化时,往往鲁棒性不足,受到很大噪声干扰,特别是实时视频中出现的各类噪声。所以在移动端基于 GAN 的超分鲁棒和实时很难兼顾,特别是 Android 机型。
3)基于视频超分,需要两帧做光流(或块匹配)、对齐、融合,非常耗时,对于不能裁剪缩小的原始输入帧,要想在 Android 机型上实时超分,几乎是不可能的。而去掉光流或对齐,则效果很难保证,还会导致超分后的视频偏模糊,对比 2019~2020 的轻量级的两帧视频超分,很多效果还不如单帧超分,特别是运动稍大或灯光闪烁或颜色渐变场景。
4)注意力机制,在超分应用中虽改善了主观效果,但非常耗时、性价比很低。
2.2 极轻量级模型设计
一般来说,轻量级超分模型设计架构如下:
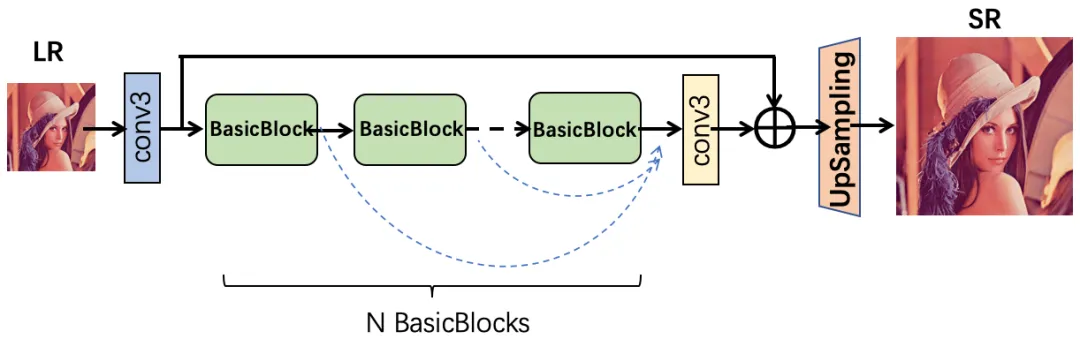
如何设计轻量级([1]~[11])的超分网络模型呢?
优化 BasicBlock 基础块,调整 Skip Connection,并且让每个卷积基础块都能充分发挥其功效而不冗余。但是这样的网络模型,在参数量、运算量极度限制的情况下,卷积个数屈指可数,特征通道数也极度有限。那么我们又该如何设计?
1)优化基础残差块:让每个卷积发挥关键性的、不冗余的作用,1×1 和 3×3 卷积是必然首选。让通道内部、通道之间进行特征信息共享,降低参数量、运算量,有效提取特征、重建;
2)优化模型设计框架:大模型训练,等价或几乎等价小模型推理,但不限于单纯的知识蒸馏等技术,并且还需结合量化做训练。
3)操作算子的选择:尽可能选择前馈推理库支持的操作算子,否则很耗时;
4)优化损失函数:蒸馏损失、梯度损失、TV损失、DCT损失、FFT损失、特征信息损失等;
5)优化训练技巧和数据集:结合实际视频业务流程,懂视频编解码,制作适合业务的训练数据集,而不是单纯的调参。实际业务中,60%靠数据,30%靠网络模型,10%靠调参训练技巧,三者互为补充。
2.2.1 优化基础残差块
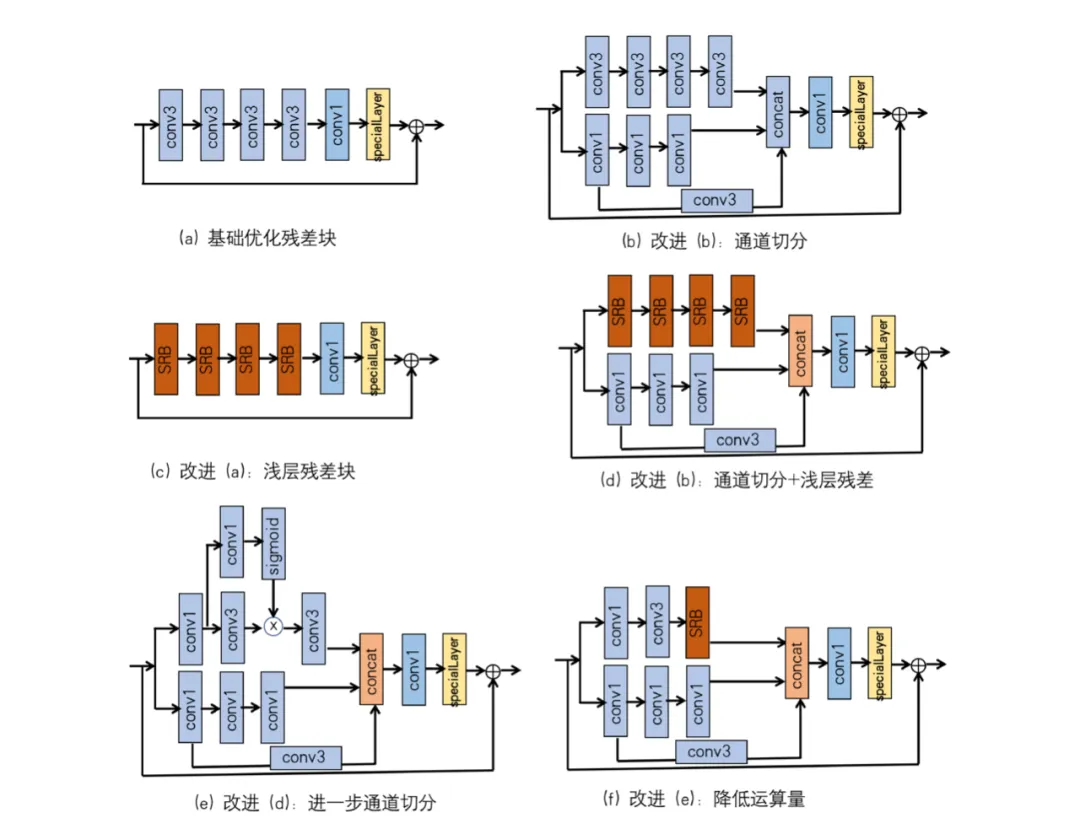
以上仅仅是优化基础残差块,做各种对比实验(主客观对比实验、整体耗时、各个操作算子耗时等),择优选择出适合自己业务逻辑的优化方向。
当设计极轻量级网络的时候,卷积的个数往往屈指可数的,就导致NAS方法(Neural Architecture Search)没有实际意义,在落地应用时实测更加耗时。同理,模型剪枝实际意义不大,特别是对极轻量级的网络模型。
2.2.2 模型框架设计
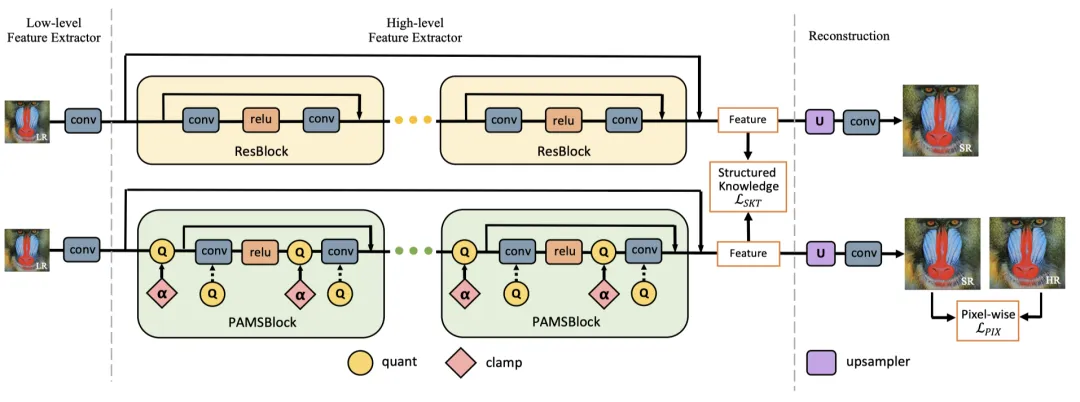
PAMS2020[11]这篇超分文章也给了我们一个思路:
1)量化及支持量化的推理库,2bit量化及支持2bit量化的前馈推理库是至关重要的,2bit量化结合大模型训练小模型推理,带来了很大的效果和性能优化空间,而不用苦苦追寻性价比下确界;
2)结构化特征信息知识损失;
3)引申出大模型训练,等价小模型推理。
2.2.3 其他优化
根据实际业务需求,利用视频图像常识做训练数据和损失函数:
1) 平坦区域总是远远高于非平坦区;
2) 人眼对平坦区超分或其他增强是无感的,而密集纹理区增强是感知强烈的;
3) 深度学习任务中,训练数据的重要性远大于网络模型设计; 基于以上基础知识,优化的知识点就出来了,无论是损失函数的设计,还是数据集的设计,即使无法涨点,但是能够提升主观质量。
2.3 模型压缩及加速
分两方面:
1) 模型压缩:对于非常小的极度轻量级的模型,剪枝、网络搜索等策略大多不太适用了;
2) 模型加速:分为以下3点
- 量化(PQT/QAT)与支持量化的推理库,需要自研支持量化的前馈推理库;
- 硬件加速,比如使用高通的 DSP(SNPE)、各个厂家的 NPU/APU、苹果的 ANE 等;
- 支持量化的硬件加速;
对于很多大模型来讲,量化后精度的下降可接受,而极小模型对精度非常敏感,精度稍微下降,主观质量也会有明显的下降。
基础对比实验
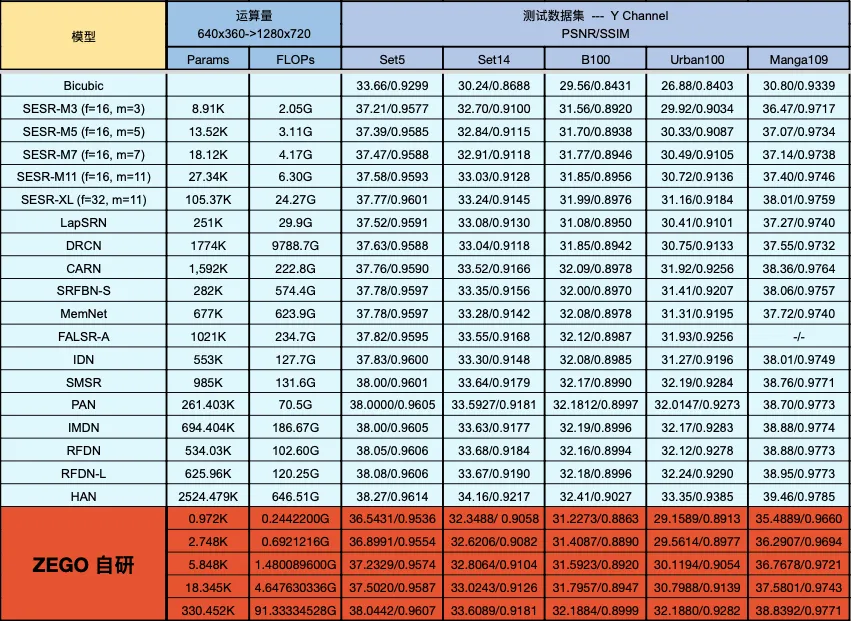
从图6各个数据集上可以看出,ZEGO 超分表现卓著:
1、ZEGO 大模型,优于 IMDN 2019(AIM 2019冠军),参数量是 IMDN 的一半,FLOPs 也是其一半;
2、ZEGO 大模型,相比于 RFDN2020(AIM2020冠军),PSNR/SSIM 略低,但参数量是它的一半,FLOPs 是其三分之二;
3、ZEGO 小模型,5.848K 参数量下,优于 SESR-M3;
4、ZEGO 最新极小极小模型,0.972K 参数量,0.24422G 的 FLOPs,性能很接近于双立方插值,而 Set5 上的 PSNR/SSSIM 为 36.5431/0.9536,还是显著优于双立方插值的 33.66/0.9299。
未来展望
高分辨率的视频能提供更清晰的画面和更高阶的感官体验,对于提升视频质量和用户视觉感受有很大的帮助。ZEGO 即构科技发布移动端实时超分辨率技术,帮助客户获得畅爽的视频体验,致力于打造更高水平的图像恢复和图像增强。
未来,即构超分将继续进行算法性能优化,提升视频效果,做到——
更快!极低功耗,极低耗时!
更好!提升视频主观质量!
更低!结合编解码,实现高清画质下的极低码率!
更广!覆盖更多机型!
附:参考文献
[1] IMDN2019: Hui, Z., Gao, X., Yang, Y., Wang, X.: Lightweight image super-resolution with information multi-distillation network. In: ACM Multimedia. pp. 2024–2032. ACM (2019)
[2] LapSRN2017: Lai, W., Huang, J., Ahuja, N., Yang, M.: Deep laplacian pyramid networks for fast and accurate super-resolution. In: CVPR. pp. 5835–5843. IEEE Computer Society (2017)DRCN2016: Kim, J., Lee, J.K., Lee, K.M.: Deeply-recursive convolutional network for image super-resolution. In: CVPR. pp. 1637–1645. IEEE Computer Society (2016)
[3] SESR2021: Bhardwaj, Kartikeya and Milosavljevic, Milos and O’Neil, Liam and Gope, Dibakar and Matas, Ramon and Chalfin, Alex and Suda, Naveen and Meng, Lingchuan and Loh, Danny: Collapsible Linear Blocks for Super-Efficient Super Resolution. (2021)
[4] PAN2020: Zhao, Hengyuan and Kong, Xiangtao and He, Jingwen and Qiao, Yu and Dong, Chao: Efficient image super-resolution using pixel attention.ECCV2020
[5] RFDN2020: Jie Liu, Jie Tang, Gangshan Wu: Residual Feature Distillation Network for Lightweight Image Super-Resolution. AIM2020
[6] SMSR2020: Longguang Wang, Xiaoyu Dong, Yingqian Wang, Xinyi Ying, Zaiping Lin, Wei An, Yulan Guo: Exploring Sparsity in Image Super-Resolution for Efficient Inference.2020
[7] Saeed Anwar, Salman Khan, and Nick Barnes. A deep jourworks. In Proceedings of the IEEE conference on computer ney into super-resolution: A survey. ACM Computing Survision and pattern recognition, pages 1646–1654, 2016. 5, 6 veys (CSUR), 53(3):1–34, 2020
[8] Zhang, Y., Li, K., Li, K., Zhong, B., Fu, Y.: Residual non-local attention networks for image restoration. In: ICLR (Poster). OpenReview.net (2019)
[9]Zhang, K., Nan, N., Li, C., Zou, X., Kang, N., Wang, Z., Xu, H., Wang, C., Li, Z., Wang, L., Shi, J., Gu, S., Sun, W., Lang, Z., Nie, J., Wei, W., Zhang, L., Niu, Y., Zhuo, P., Kong, X., Sun, L., Wang, W., Timofte, R., Hui, Z., Wang, X., Gao, X., Xiong, D., Liu, S., Gang, R.: AIM 2019 challenge on constrained super-resolution: Methods and results. In: ICCV Workshops. pp. 3565–3574. IEEE (2019)
[10] Zhang, K., Danelljan, M., Li, Y., Timofte, R., et al.: AIM 2020 challenge on efficient super-resolution: Methods and results. In: European Conference on Computer Vision Workshops (2020).
原创文章,作者:ZEGO即构科技,如若转载,请注明出处:https://market-blogs.zego.im/reports-technique/380/