前言:本文结合实际业务场景进行思考,介绍 ZEGO 即构科技在高可用架构和运营上所进行的探索和实践,希望对大家能有所帮助或启发。
背景与挑战
全球网络复杂多变,各个地区的网络基础设施参差不齐,常常会因为机器宕机,机房故障,IDC之间公网链路抖动导致推拉流失败或者视频质量变差。在应对以上这些不可抵抗因素带来的问题时,ZEGO 是怎么做的呢?
首先,向大家介绍一下几种比较常见的故障场景:
- 单机故障
- 机房故障
- 突发超大流量
- ZEGO 外部服务故障
- 控制中心/集群故障
- 机房之间局部网络线路故障
其次,在流媒体边缘节点接入终端用户网络时,主要面临以下挑战:
- IP 解析可能不准确
- 用户网络环境 UDP 协议限制
- 用户网络环境端口限制
- 用户网络环境存在多出口环境
- 云商节点对某个运营商接入不好
下面将详细讲述 ZEGO 即构科技是如何设计可用率高、容灾容错能力强的 RTC 系统,来解决上述的问题与挑战,给客户构建稳定的 RTC 使用体验。
即构应对不同故障问题的处理方式
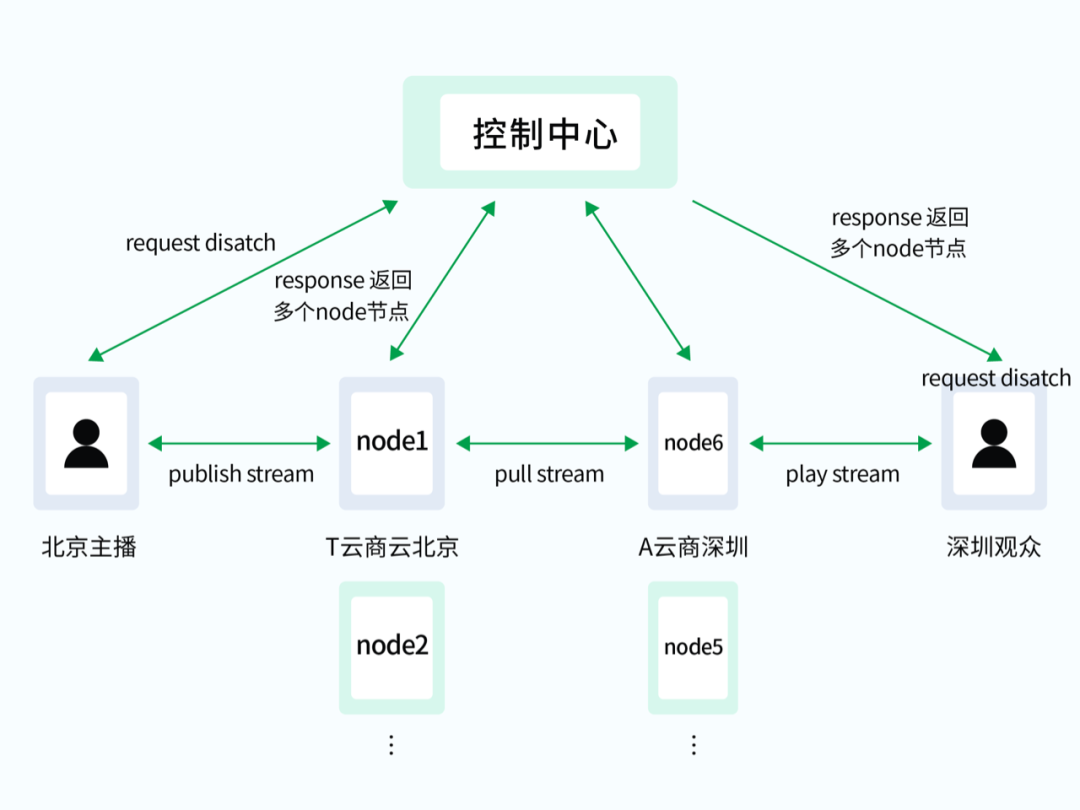
一个简单的应用场景:北京的一个主播发起调度请求,控制中心使用就近接入的策略下发一个 node 节点列表:[ip1:port,ip2:port,ip3:port…],默认优先使用第一个节点进行推拉流,这样主播就实现了向 node 1 推流。深圳观众一样进行调度请求得到 node 6 节点,对节点发起拉流请求,node6 对 node 1 进行服务器间的内拉将流串起来,就实现了一个简单的推拉流场景。
{kind=link}

- 单机故障
单机故障比较常见,一般只需多机部署即可。故障时自动剔除异常节点,ZEGO SDK 支持重试逻辑,连接断开后重试一下个节点即可。如图1,北京主播请求调度时,会得到多个 node 节点,当 node1 故障时,SDK 会自动重试到node2。
- 可用区/机房故障
这种风险的概率比单机器的要低很多,但是也不是完全不可能发生,在实际情况中,还是有一定概率的。 最为常见的就是通往机房的光纤被挖断了或者 DDOS 攻击导致一些区域的 IDC 不可用或者网络质量变很差。ZEGO 一般采用多机房部署的方案,调度结果返回的时候至少包含了 2 个及以上机房的节点,SDK 会重试到正常的机房。
3. 突发超大流量
这种风险还是比较普遍的,ZEGO 主要有以下点的手段防控:
- 服务对外的接口本身都有做限频,限流,熔断的措施;快速的自动扩容机制;
- 运维上漏斗模型部署,最外层的服务容量能力要低于下一层的容量,在最外层限制流量保护现有的流量;
- 客户接入时分桶接入。除了数据层共享外,服务节点隔离部署。某个客户突发大流量时,可以避免影响更多的客户。
- ZEGO 外部服务故障
以转推 CDN 的故障为例,有转推质量差和转推失败两种情况,ZEGO 主要有以下点的手段解决:
- 转推失败时,服务会依赖 CDN 域名解析的 IP 进行轮询重试;
- 转推质量差一般是指 ZEGO 节点到 CDN 节点之间网络抖动导致视频流卡顿等。质量差的根本原因可能是 CDN 节点本身问题,也有可能节点本地 DNS 解析错误导致,针对转推的节点质量差,ZEGO 自研智能探测和调度机制可以使 ZEGO 节点获取到当前最佳的 CDN 节点列表。
- 控制中心/集群故障
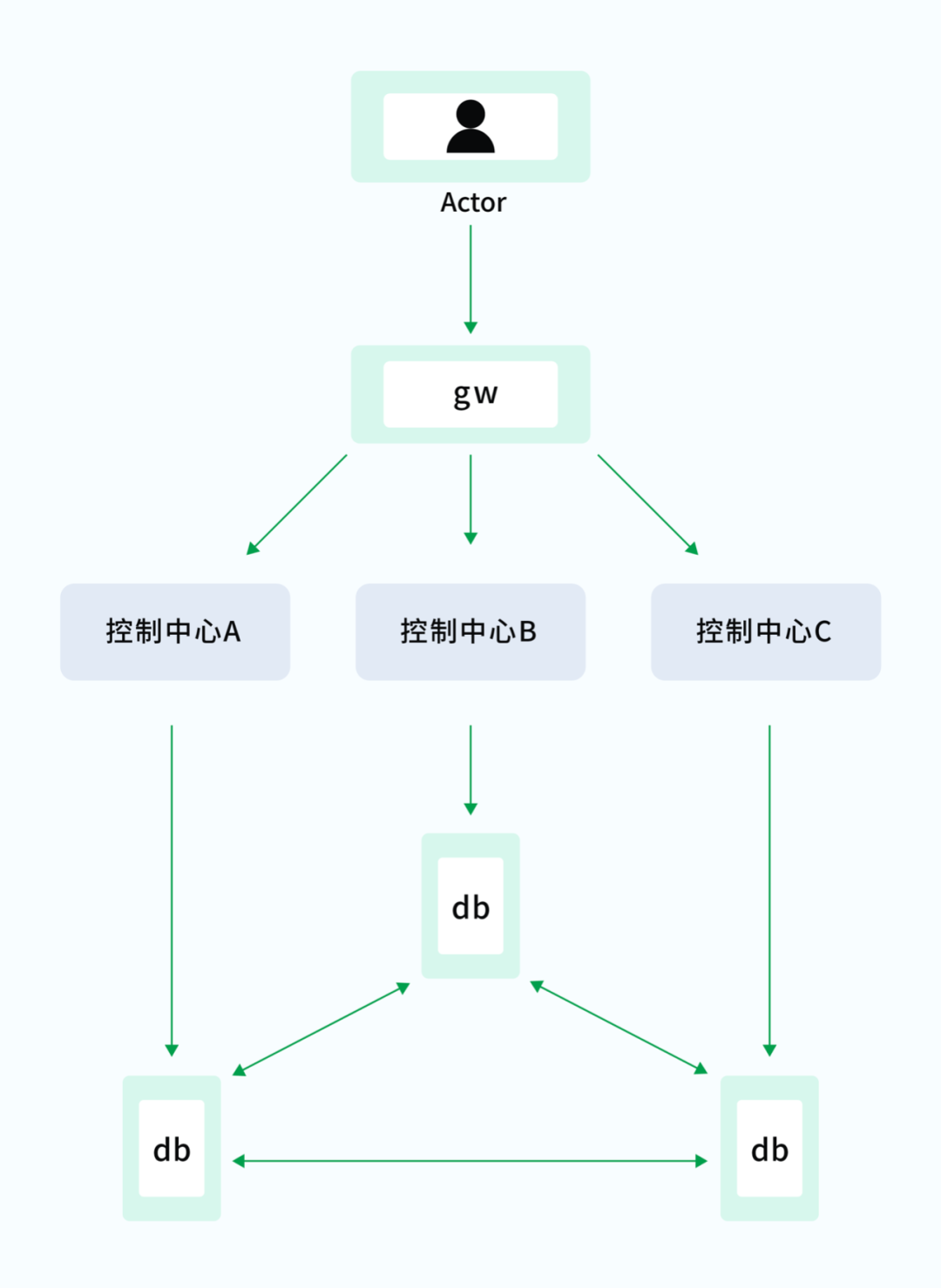
一般控制中心故障这种概率极少出现,当整个控制中心故障时一般意味着某个云商的整个地区所有机房全部故。 面对这种灾难级别的故障,ZEGO 实现了全球多中心架构。当控制中心 A 故障时,可以及时关闭故障中心的入口。可参考图 2,多中心简易版架构图:
- 机房之间局部网络线路故障
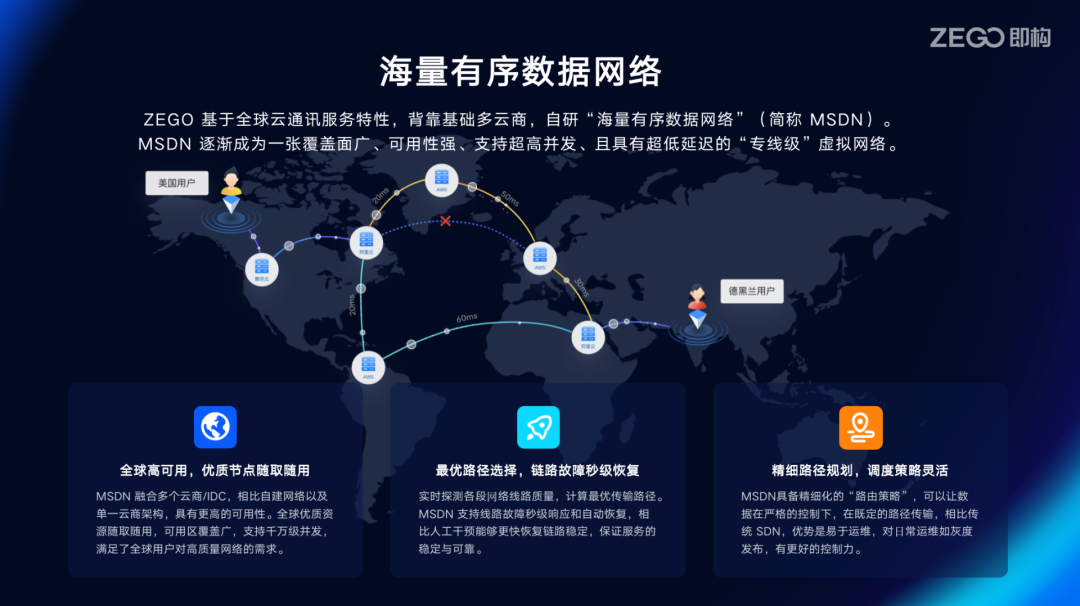
ZEGO 本身是多云商全球部署,节点与节点之间公网链路经常抖动。如何解决这一行业痛点?ZEGO 自研智能路由MSDN 系统,下面将介绍我们对于 MSDN的建设和探索。 ZEGO 依托主流云商的全球节点,全球 200+ 机房部署无死角覆盖,自研 MSDN 服务构建全球可靠的多云通讯链路。 可以简单向大家介绍一下 ZEGO MSDN 的核心设计理念: 通过自建 3 层数据转发网络,源和目标节点通信规划多条链路,实时探测,优先走最优线路,当前线路故障时或者质量变差时无缝切换线路。
下面通过一个实际的案例来介绍 ZEGO MSND 如何解决的机房之间网络故障这一问题。 案例介绍: 在 01-15 15:00 左右 T 云商孟买到 A 云商法兰克福公网出现高丢包的情况,链路质量变差,如图 4:
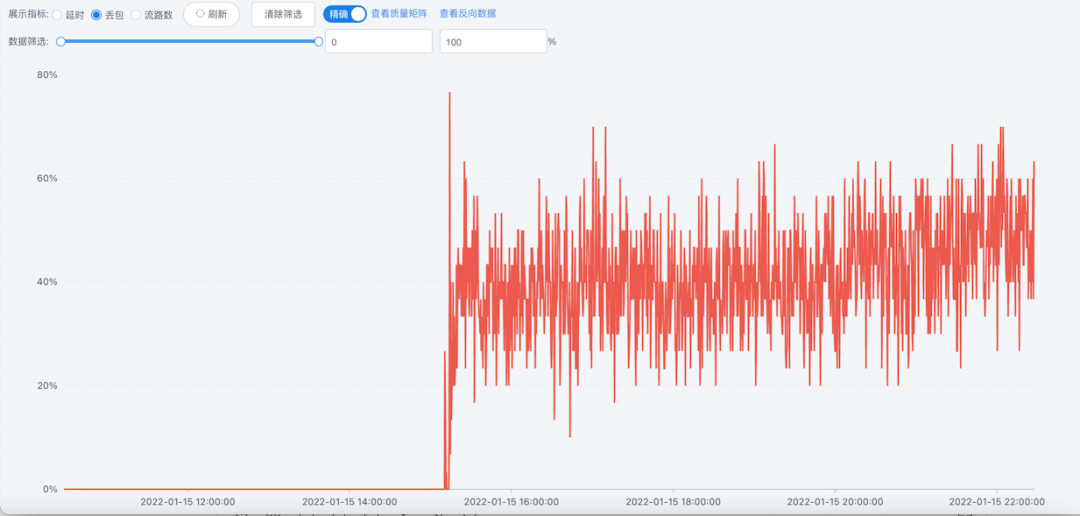
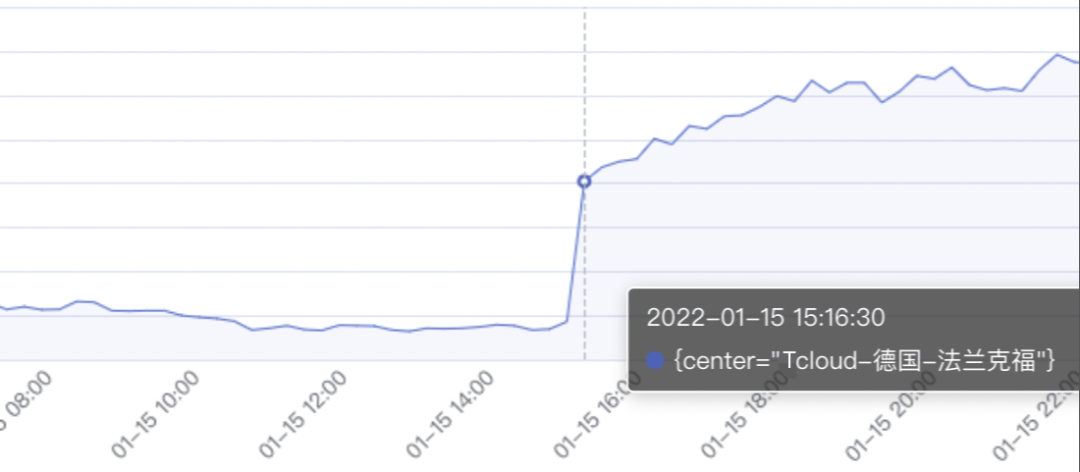
随后 MSDN自动触发链路切换:如图 5,切换后链路变成孟买(T 云商)–>法兰克福(T 云商)–>法兰克福(A 云商)
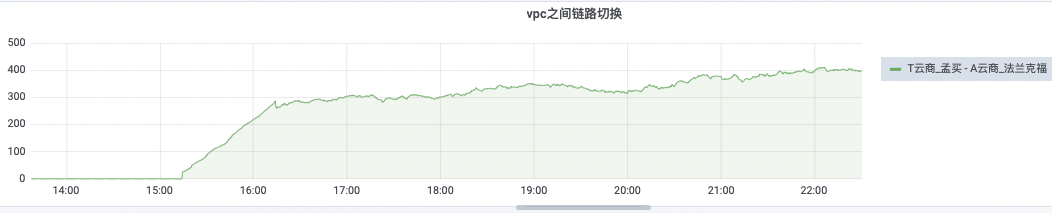
由于线路切换,法兰克福(T 云商)流量出现了上涨,如图 6:
总结:由于 T 云商孟买到 A 云商法兰克福公网出现高丢包情况,MSDN 自动切换链路,切换后链路变成孟买(T 云商)–>法兰克福(T 云商)–>法兰克福(A 云商),整个过程完成了无缝切换,用户无感知。
流媒体边缘节点如何最优接入终端用户的网络
- 如何解决 IP 解析不准确问题?
这个现象比较普遍,IP 库的不准确直接影响到的是用户的体验,比如一个非洲的 IP 解析到美国,带来的结果就是用户连接到的是 ZEGO 美国的节点。有时已经明确某个 IP 解析不准确的情况,提交反馈至 IP 库厂商,往往需要较长的周期,才能有新版本修复。 针对以上情况,ZEGO 对已知解析错误的 IP 或者 IP 段进行修正,并定期探测扫描 IP 段变化情况,及时更新服务来解决问题。
- 如何解决用户网络环境 UDP 协议限制?
这种问题比较常见,一般受限于用户的路由器交换机等设备的限制,UDP 协议被禁止,导致无法和流媒体节点进行通讯。ZEGO 的流媒体节点本身提供了 UDP,TCP 多协议的能力,当用户协议受限时 SDK 会尝试切换协议进行流媒体通讯。
- 如何解决用户网络环境端口限制?
这种问题也比较常见,办公环境一般比较常见,有些公司考虑安全问题某些端口被禁止。ZEGO 在调度策略上进行了优化,提供调度返回的节点一般是不同端口,当客户端口受限时 SDK 会尝试切换节点进行流媒体通讯。
- 如何解决用户网络环境存在多出口环境问题?
这种情况也比较常见,公司办公室考虑容灾情况一般是拉两条不同运营商的线路接入,还有的公司存在更复杂的环境,比如路由限制有些流量走 VPN 出口。多出口网络环境为啥会影响到用户体验呢? 举个例子: 用户发起调度请求的时候使用出口网络使用的是 VPN (假如 VPN 到了美国),此时被 ZEGO 调度服务识别到是美国的用户发起的请求就优先返回了美国流媒体节点;当用户对媒体节点进行连接时网络出口切换为了默认(假如默认是广东移动线路),就变成了一个广东移动的用户连接美国媒体节点的状况,这样的质量肯定是比较差的。
那么 ZEGO 是如何解决的呢? ZEGO SDK 结合服务端进行了优化。
原理是:当用户连接上媒体节点时,媒体节点会将感知到的用户客户端 IP 反馈给SDK,SDK 通过对比调度客户端 IP 发现不一致时,SDK 发以媒体节点感知到的客户端 IP 再次发起调度,这样就拿到了和用户实际推拉流网络环境匹配的流媒体节点。
5. 如何解决云商节点对某个运营商接入不畅?
网络环境本身是复杂多变的,怎么较好的接入终端用户?这也是挑战最大的点,ZEGO 分别从 SDK 视角和后台服务视角分别做了优化。
1)SDK 侧的优化点:实时探测和动态调度逻辑
- 首先是实时质量探测,如果用户首次登陆,SDK会对调度结果进行多个节点质量探测,获取质量最优节点进行连接。
- 其次是对于已有推拉流记录的用户,SDK根据历史数据驱动计算最优节点进行动态调度。
- 最后对于已连的上节点使用过程中质量不好,rtt 和丢包率比较高。SDK 会再次对所有节点进行探测,选择质量最优的节点进行重新连接。
2)后台服务侧的优化点:后台通过质量运营系统的大盘分析反馈调度系统,进行动态调整集群的调度策略
- 通过质量算法对终端用户的网络进行打分来评价推拉流质量的好坏,具体算法可以理解为当用户的 rtt 和丢包率落在较好的区域是是加分,落在坏的区域是减分,rtt 和丢包越小加分系数越高,rtt 和丢包越大减分系数越高得出一个百分制分数。
- 通过这个分数就可以进行多维度的数据分析,可以单独看国家维度的分数来衡量一个国家整体的接入质量是怎样的如图 7 是 top5 国家的质量分数;细的维度可以得出国家,一级行政区,ISP,IDC 机房的质量分数,当发现某个国家某个地区的某个运营商质量分数持续下滑时,质量运营系统将分析出最优的机房覆盖同步至调度服务,调度服务结合机房容量等因素进行实际的调度调整来恢复质量。
- 当然调度依赖质量运营系统的反馈时间会有稍有滞后,比较适合较长时间未恢复的情况。对于分钟级网络抖动情况,节点机房会对所覆盖区域的国家的主流运营商进行实时的探测,当发现机房对某个运营商质量下滑时进行比较及时动态调整。
总结与展望
以上即是 ZEGO 即构科技在高可用运营和能力保障方面的介绍, ZEGO SDK 的重试逻辑,服务端的容灾部署方案,多中心架构的设计,MSDN 的应用等手段对于提高服务的 SLA 有着重要作用。
对 RTC 的高可用运营不仅是一个热门的研究方向,更是一个复杂的系统,这里只提及了部分工作,我们将持续进行探索优化,给客户提供高质量的服务体验!
原创文章,作者:ZEGO即构科技,如若转载,请注明出处:https://market-blogs.zego.im/reports-technique/387/