我们已经知道,音频编码过程是压缩、减少数据量的过程,但“减少”并不代表可以随意丢弃,而要在减少“数据量”时,同时尽可能避免“信息量”的丢失,也即保真。如果被压缩的音频数据,其所有信息可以被完整地解压、还原,我们称相应的处理为无损压缩;否则,相应的处理即为有损压缩,有损压缩能够带来更好的压缩效益,是 RTC 场景下普遍使用的方案,我们今天也着重了解有损压缩相关的技术点。
值得一提的是,有损和无损也是相对而言的,目前任何数字编码方案都无法做到完全无损,就像用数值表达圆周率 π = 3.1415926……,只能无限提高精度、无限接近,但永远无法相等。
注:PCM 就属于“无损”的音频编码,我们已了解其原理是对模拟音频信号在时间轴、幅度轴上进行采样、量化处理,以使重构的语音波形尽可能与原始语音信号的一致,其保真度好,但编码码率很高,不适用于RTC场景。
那么,既然是“有损压缩”,实现可观的压缩率,又要最大限度避免“信息量”丢失,这不是相互矛盾了吗?
其实,“信息量”再加上一个定语会更贴切,那就是避免“有用、重要的“的”信息量丢失。压缩过程中丢弃的数据相对于整体应该是“不必要”或“不重要” – 也即“冗余”的。在 RTC 场景中,人是音频信号的消费者,我们可以充分利用人耳听觉的生理、心理特性来寻找这些“不必要”、“不重要”的冗余成分,总结下来主要包括两方面:
1 人耳听觉范围之外的音频信号
在系列第一讲-音频要素 中,我们了解到:人耳的听力范围仅限于频率 20Hz ~ 20kHz,低于或者高于该频率范围的声音无法被人耳感知,被称为次声波(<20Hz)和超声波(>20KHz)。这部分“无法被人耳感知”的声音,就属于音频信号中“不必要” 的“冗余”部分。同时,因为不同类型信号的频率特征不同,比如语音的频率集中在 300 ~ 3400Hz,如果只关注语音信号,300~3400Hz 频段之外的信号也可以视为“冗余”,可以在编码压缩过程中“丢弃”。


2 被掩蔽掉的音频信号
除了对特定频率的声音不敏感外,人耳还会因为“掩蔽效应”而忽略某些“弱音信号”。关于“掩蔽效应”,我们以响度(声强级)作为参考(详见系列课程第四讲-音频AGC),做如下理解:
人耳对于不同频率的声音,有相应的最小响度可闻阈,如果某个频率的声音响度小于该频率的最小可闻阈,该声音将无法被人耳听到。并且,某一频率声音的最小可闻阈不是固定的,当存在能量较大的“强音信号”时,该“强音信号”附近频率的“弱音信号”的最小可闻阈值会提高,这就是掩蔽效应中的“频域掩蔽”,如下图【频域掩蔽】所示。
除了频域掩蔽外,当强音信号和弱音信号同时存在时,在不同时机,还会有“时域掩蔽”。如下图【时域掩蔽】所示,在强音信号出现前的短时间内(约20ms),已经存在的弱音信号会被掩蔽;当二者同时存在,弱音信号会被掩蔽;当强音信号消失后,还需要等上一段时间(约150ms),弱音信号才能重新被人耳听到。以上三种类型的时域掩蔽分别称为超前、同时和滞后掩蔽。
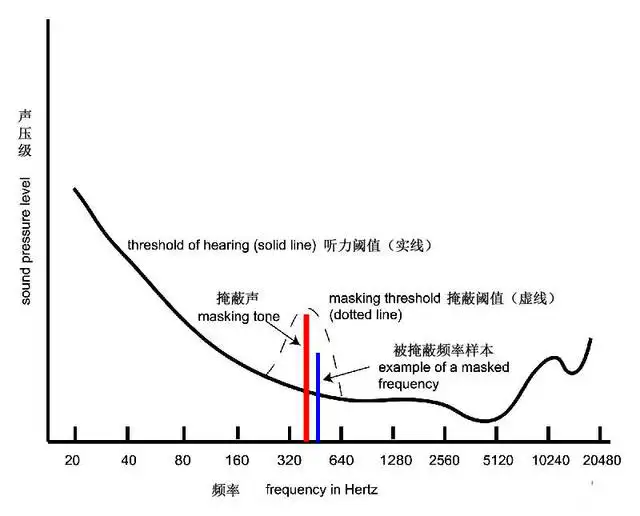
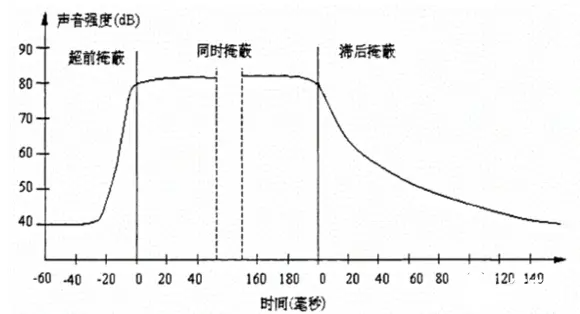
在频域掩蔽和时域掩蔽中,那些“被掩蔽的信号”无法被人耳感知,所以可以视为冗余信号,可以在编码压缩过程中“丢弃”。
除了利用人耳听觉的生理、心理特性定义的“冗余”外,基于信息论原理,音频信号在时域和频域上的特征具有统计相关性,也即存在数据冗余,这些冗余也可以通过信息编码的方式进行压缩处理。
综上,我们从声音信号中找到了“冗余”成分,它们是支撑音频编码压缩的“可行性”基础。
现在,我们已经了解了音频编码压缩的必要性和可行性,接下来该聊聊具体的音频编码格式了。
音频编解码技术的发展历经了多个阶段,从针对语音信号的时域编解码、到针对音乐信号的频域编解码,最后也演变出同时兼顾两种类型信号的“全能编解码”,关于发展史大家灵活使用搜索引擎可以了解到很多干货,在此不做赘述。
目前,已经有诸多成熟的方案供我们选择,除了前面提及的 AAC ,常见的音频编解码格式还有:OPUS、SILK、SPEEX、MP3、iLBC、AMR、Vorbis、G.7 系列等等,而在 RTC 应用中常用的有 AAC 和 OPUS,我们下篇文章将重点了解这两种格式,并会围绕音视频业务开发者关注的:编码方案的优缺点、如何根据场景来灵活选择等维度进行讲述。
原创文章,作者:ZEGO即构科技,如若转载,请注明出处:https://market-blogs.zego.im/reports-technique/514/