我们今天讨论的噪声,无论是稳态还是非稳态,都是相对于“有用的声音”(人声)的加性噪声。加性噪声和人声不相关,人声的存在与否不影响加性噪声的存在性,它们的混合信号可以通过相加得到。
噪声抑制原理解析
本文针对 RTC场景下的噪声,第一步,要了解噪声抑制的基本原理。
1 噪声抑制原理的简单理解
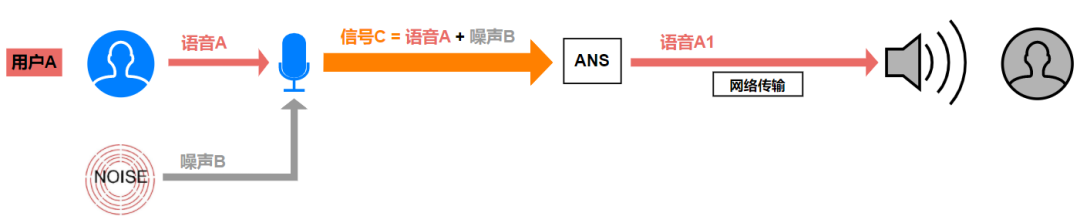

回想一下,我们在上一篇课程中学习的,回声消除的关键工作:使用待扬声器播放的远端参考信号,估计出回声信号,在麦克风采集的混合信号中将回声信号减去,保留近端语音。这一过程,只需要稍作调整就可以对应到噪声抑制上:估计出噪声信号,并将之从麦克风采集的混合信号中除去,得到降噪语音信号。如上图所示,稳态或非稳态的“加性噪声” B,和“有用信号”语音 A 相加,形成了混合的带噪语音 C1,经过 ANS 模块的处理后,最终输出降噪语音 A1。
即:
C = A + B
A1 = C – B1
虽然核心工作也就短短一句话,但其中玄机不少。传统 ANS 算法的核心工作可以拆解为两个模块:噪声估计模块 + 噪声滤除模块。
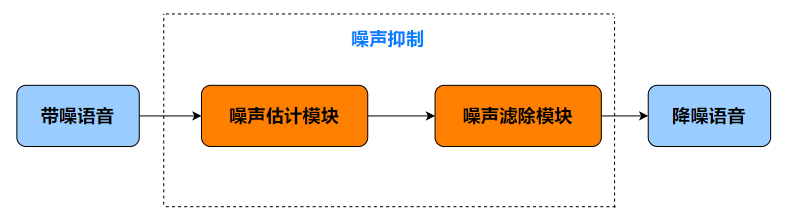
2 噪声估计模块
噪声估计模块的主要工作是:判断当前信号是语音还是噪声,以及噪声的量。相较于回声估计,噪声估计的差异在于:噪声并非由远端参考信号变化得到(加性噪声),而有其独立的发声源,无法像回声一样利用其和远端参考信号的相关性来估计,大多数情况下,我们的原材料是有混合带噪语音 C。噪声估计的准确性是至关重要的,但要从混合信号中,估计出其一部分,听起来似乎有些难为人?好在方法总比困难多,凡事都有两面性,既然无法利用“相关性”进行估计,不如试试从“不相关性”下手。
我们先看看下面两种噪声估计的方式:
- 基于谱减法的噪声估计
基于谱减法的噪声估计,一般会认为带噪语音的前几帧不包含语音活动,是纯净的噪声信号,因此,可以取这前几帧的平均信号谱(幅度谱或能量谱)作为噪声谱的估计。
- 基于语音活动检测(VAD)的噪声估计
基于语言活动检测的噪声估计,会对混合信号 C 进行逐帧检测,如果某音频帧经VAD检测没有语音,则认为是噪声、并更新噪声谱,否则就沿用上一帧的噪声谱。
上面两种方法,往往都需要比较纯净的噪声段,并希望噪声尽可能的稳定,这对于待处理信号的要求就比较高,对于复杂多变的实际应用场景来说就显得尤其苛刻了。
- 基于统计模型的噪声估计
在 RTC 场景下,通常会采用另一种方案:基于统计模型的噪声估计。
基于统计模型的噪声估计,一般需要语音信号和噪声信号是统计独立的(不相关),并服从特定的分布,以将问题归入到统计学的估计框架中。开源 WebRTC 的降噪模块,也使用了基于统计模型的估计方式。我们不妨通过学习 WebRTC 的降噪模块的估计方案,来帮助了解。WebRTC的噪声估计过程如下:
- 首先,进行初始噪声估计:使用分位数噪声估计法。基于一个共识,即使是语音段,输入信号在某些频带分量上也可能没有信号能量,可以对某个频带上所有语音帧的能量进行统计,设定一个分位数值,能量低于分位数值的认为是噪声,反之则认为是语音。这种方式,相比于 VAD 的逐帧判断,进一步细化了噪声统计的粒度,即使是语音帧也能提取到有效的噪声信息。
- 然后,更新初始噪声估计:初始噪声估计的结果是不够准确的,但可以作为初始条件应用于噪声更新/估计的后续流程 – 基于似然比函数改造的噪声估计:将多个语音/噪声分类特征合并到一个模型中,结合模型以及初始噪声估计的先验/后验信噪比,对输入的每帧频谱进行分析,计算某一帧是音频/噪声的概率来判断是否为噪声,进一步更新初始噪声估计。
- 更新后的噪声估计会比初始估计更准确,更新后需要重新计算一下先验/后验信噪比,再用于后续的噪声滤除模块
综上,就是WebRTC使用的一些噪声估计方案,我们从噪声估计模块得到了比较准确的噪声信息,接下来就是 ANS 的另一个关键步骤:噪声滤除模块。
3 噪声滤除模块
噪声滤除的方式也有多种,比如前面提到的谱减法,使用带噪语音的信号谱减去估计的噪声谱,就得到了估计的干净信号谱。但我们说过,这种方式不适用于复杂多变的 RTC 场景,所以干脆一步到位,直接来了解 WebRTC 使用的噪声滤除手段:基于维纳滤波器的噪声滤除。
什么是维纳滤波器呢?
如下图所示:将带噪语音 A 输入一个噪声滤波器,如果期望的输出信号为 A1,实际的输出信号为 A2,通过计算得到 A1 和 A2 的估计误差 E。我们希望 A2 尽可能的逼近 A1,那么估计误差 E 就应该尽可能小,而能实现这个目标的最优滤波器就是维纳滤波器。
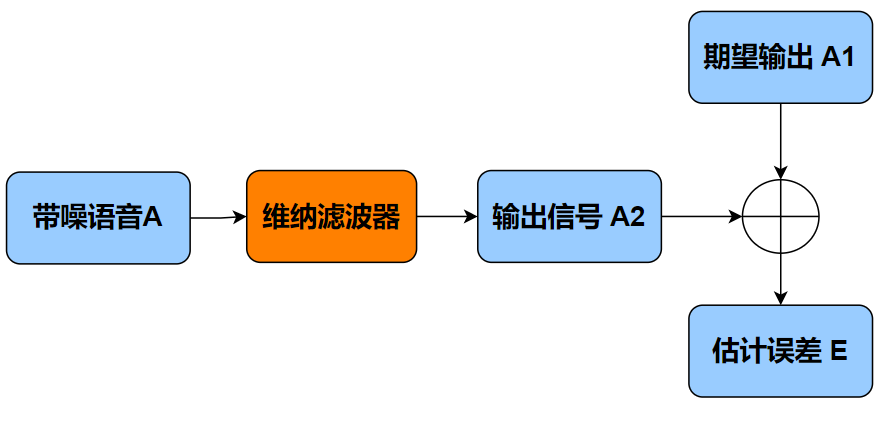
维纳滤波器是一种线性滤波器,其数学表达式的推导需要用到语音信号的先验/后验信噪比,如此一来,前面噪声估计模块的输出信息就有了用武之地。通过这些信息,我们就可以将 WebRTC 的噪声估计模块、噪声滤除模块衔接起来了。
现在将两个模块结合起来,总结一下其核心逻辑:
- 首先利用分位数噪声估计法得到噪声的初始估计,并基于该估计计算后验/先验信噪比;
- 接着,利用基于似然比函数的改造算法、以及整合了语音/噪声分类特征的模型,分析每帧频谱得到每帧语音/噪声的概率,利用概率判断噪声、进一步更新更准确的噪声估计;
- 基于更准确的噪声估计重新算后验/先验信噪比、推演出维纳滤波表达式;
- 最后,使用维纳滤波完成降噪,得到降噪语音。
原创文章,作者:ZEGO即构科技,如若转载,请注明出处:https://market-blogs.zego.im/reports-technique/545/