“图像的基本组成单元为像素,对视频图像的存储,实际上是对像素的存储”。基于图像位深,我们可以确定存储一个像素所需的字节数,下面,可以开始“指导”计算机如何定量读取图像数据了。
像素在图像中是一行一行排列、并逐行存储在内存中的,计算机在读取图像时,就需要逐行地、正确地读取出每一行的像素。这里就引出两个问题:每一行究竟有多少个像素?计算机每获取一行数据需要读取多少个字节呢?要解答这两个问题,我们需要再学习两个概念:图像的宽高 (Width、Height) 和跨距 (Stride)。
1 图像宽、高
说到图像的宽高,大家直觉上可能会联想到 “厘米”、“英寸” 等长度单位,其实,从图像处理的角度并非如此。在视频图像处理上,描述图像宽高时,通常使用的是“计数单位”,而其具体的数值,则由图像的分辨率决定。
关于视频图像的分辨率,在系列推文中还没有和大家正式介绍,但大家对 “分辨率” 肯定是不陌生的。在各大视频/图片网站上、在各种视频/图像文件规格中,我们常看到诸如 540×960(540P)、720×1280(720P)、1080×1920(1080P)等参数,它们就是所谓的分辨率,其表示的含义为:图像在水平方向、垂直方向上,每行、每列的像素 “个数”。
- 宽(Width):水平方向每行的像素个数,等于图像分辨率的宽
- 高(Height):垂直方向每列的像素个数,等于图像分辨率的高
如下图所示,对于分辨率为 540×960 (宽 x 高)的 RGB 图像,其水平方向每行有 540 个 RGB 像素,垂直方向每列有 960 个 RGB 像素。
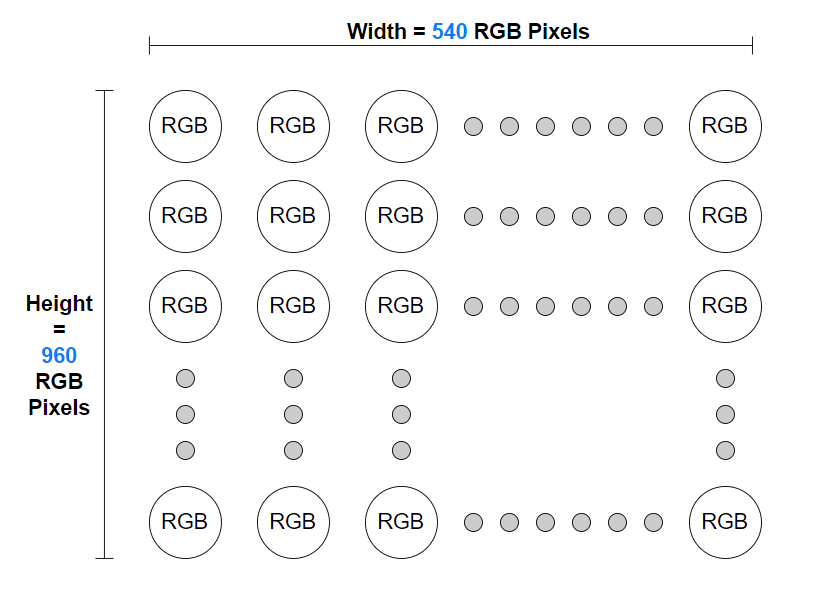

不难发现,分辨率宽高相乘得到的数值 = 图像中像素的总个数,540 x 960 的 RGB 图像中包含 518400 个像素,分辨率越高,像素的个数也就越多。
关于分辨率的知识,我们今后还会有专题作进一步讨论,今天大家了解到分辨率与图像宽高、像素个数的关系即可。
现在,我们已经通过分辨率信息,确定了图像每行的像素个数,可以尝试计算每行数据的长度(字节)。因为视频图像的处理通常是逐行进行的,计算机更关注每行有多少数据,而对于具体有多少行(Height)没有太多的要求。
以 24bit 的 RGB 图像为例,假设分辨率为 538 x 960,因为每个像素的 R、G、B 分量都连续存储在同一平面上(详见前文 色彩和色彩空间-中篇),我们可以通过如下步骤,计算每行像素的字节长度:
- 每行像素的个数 = 图像分辨率宽 = 538
- 每行像素的字节长度 = 像素位深 x 每行像素的个数 = 24 bit x 538 = 1614 byte( 注:1 byte = 8 bit)
如上,我们得到结论:对于分辨率为 538 x 960 的 RGB 图像,每行有 1614 byte 数据。计算过程看起来清晰明了,有理有据,于是我们信心满满地将 1614 byte 这个字节长度告知计算机,计算机也一丝不苟地按要求去读取一张 538×960 的图片。却可能会得到如下的结果:


我们发现,实际渲染出来的图像,呈现出规则的斜条纹,与原图相比已面目全非。
为什么会出现这样的问题呢?难道是计算机出现了 Bug ?或者说,计算机是无辜的,图像每行的像素个数实际上并不等于图像的分辨率宽度 ?要解答这些问题,我们就需要了解另外一个概念:跨距 (Stride)。
我们发现,实际渲染出来的图像,呈现出规则的斜条纹,与原图相比已面目全非。
为什么会出现这样的问题呢?难道是计算机出现了 Bug ?或者说,计算机是无辜的,图像每行的像素个数实际上并不等于图像的分辨率宽度 ?要解答这些问题,我们就需要了解另外一个概念:跨距 (Stride)。
2 图像跨距
我们知道,计算机的处理器主要是 32 位或 64 位的,当处理器执行运算时,一次读取的完整数据量最好为 4 字节 或 8 字节的倍数。如果我们要求计算机读取非 4 字节或 非 8 字节对齐的数据,它就需要进行额外的处理工作。额外工作的引入,势必会影响效率和性能。为了规避这样的问题,就需要在原始数据的基础上,再增加一些“无效数据”,使待处理的数据量对齐到 4 字节 或 8 字节 。这样计算机才能以最高效的方式工作。当然,对齐规则也不一定是 4字节/8字节 的倍数,实际仍取决于具体的软硬件系统。
回过头来,看看前面计算得到的 “1614 byte”,大家是否发现问题了呢?
是的,这并非一个 4 字节或 8 字节倍数的数值。所以,基于前述的考量,如果在一个要求 4 字节 或 8 字节 对齐的系统内存中存储该图像,往往需要增加一些额外数据,将 1614 byte 对齐到比如 1616 byte。而这里的 1616 byte,即称为图像的跨距 (Stride)。
跨距 (Stride),是图像存储在内存中,每一行数据所占空间的真实大小,它大于或等于通过图像分辨率宽度计算的字节长度。每读取一个 Stride 长度的数据,意味着完整读取了图像的一行,下次读取就该“换行”了。其中,用于补齐至 Stride 而增加的额外数据,我们称之为填充(Padding)。Padding 仅影响图像在内存中的存储方式,无需(也不可以)用于实际渲染。
我们可以通过下图,直观的理解 Width 、Padding 和 Stride 的关系。
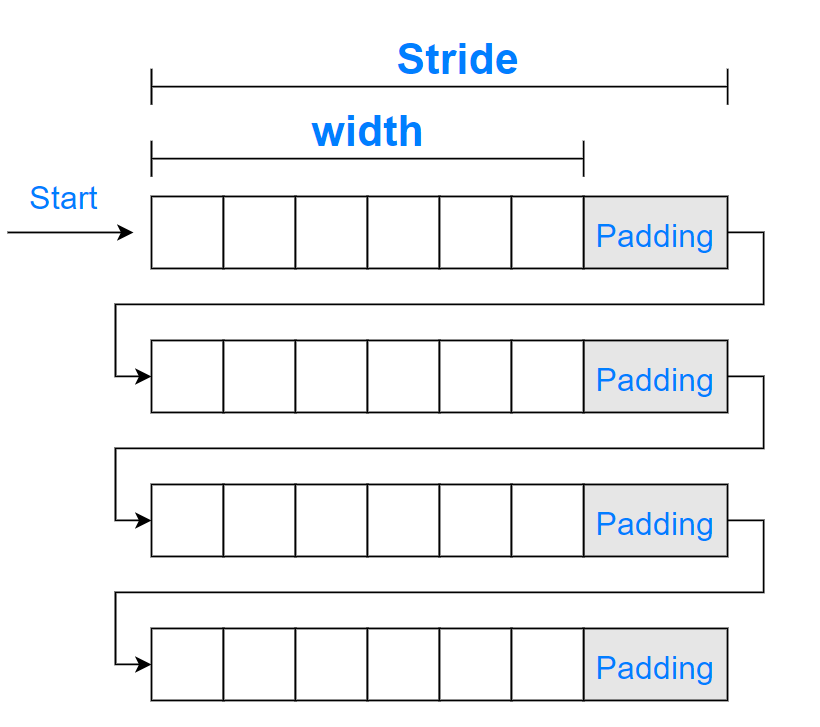
参考上图,从 Start 位置开始, 计算机只有按 Stride 读取每一行图像数据,再按 Width 进行实际的渲染,避免将无效的 Padding 渲染出来,才能显示出正常的图像。如果仅使用 Width 计算 Stride(比如上面,我们告诉计算机将 Stride 设置为 1614 byte),那么就可能会误将部分 Padding,视为有效的图像数据进行渲染,行与行之间的像素相对位置也将发生累计偏移,出现诸如斜条纹等异常。
我们也可以通过一些简化的方式,来理解斜条纹产生的原理。
参考下图,我们先忽略“字节长度”,简单地把图像数据、填充数据的单位都统一至“像素”。假设原图的 Width x Height = 6 x 8,存储时将 Stride 对齐为 8。图中彩色部分为真实图像(原图左侧),黑色部分为填充的 Padding(原图右测),中间存在的空白间隙仅为方便区分。

若使用正确的配置, Stride = 8 进行读取,Width = 6 进行渲染,则仅会显示出彩色部分, 黑色部分的 Padding 在渲染时会被忽略。
如果使用错误的 Stride = 7,正确的 Width = 6,会出现如下问题:从第一行开始,少读取了一块 Padding,并将这部分少读取的 Padding ,误当作第二行的 “有效图像” 进行读取、排列。最终,计算机再以 Width = 6 进行渲染时,将得到如下图像,出现了右侧下沉的斜条纹效果。

同理,Stride 偏大、Width 偏大、Width 偏小,都会影响图片的读取和渲染,大家在处理时需要注意。我们在下面也展示出相关的简化参考图:


注意,实际应用中如果 Padding 数据被错误渲染出来,不一定都是黑色的,具体由填充的数据而定。如果都使用 0 值填充,那么 RGB 图像的 Padding 为黑色,YUV 图像的 Padding 则为绿色。其他可能的错误情况,大家可以自己尝试推演一下,在此就不过多展开。
3分平面 YUV 的 Width、Stride
上面对于 Width 、Stride 的讨论,都是基于 RGB 图像来举例。对于 RGB 图像,其色彩空间分量是同一平面、连续存储的,一般只需考虑一个平面的 Width 和 Stride。
而 YUV 图像比较特殊,它可能使用分平面( Planar 、Semi-Planar )的存储方式(详见色彩和色彩空间-中篇)。
从整个图像的角度看,YUV 图像的每一行依旧有 Width = 720 个像素。但是从存储的角度看,Y、U、V 分量可能存放在不同的平面,计算机想要理解 YUV 色彩,就需要知道:在每个平面上、每次要读取多少数据,才能正确地组合成原始图像的一行像素。
“在每个平面上、每次要读取多少数据”,意味着需要知道每个平面的 Width 和 Stride。而考虑到 U、V 分量相对于 Y 分量可能有降采样,各个分量平面的 Width、Stride 可能不同, 必需要按存储规则分别求取。
下面,我们针对常见的 YUV 格式:I422、 I420 和 NV21 ,具体讨论一下,何谓分平面的 Width 和 Stride。
我们将基于通道位深 = 8 bit,图像分辨率 Width = 720,Height = 1280,展开后续内容的讲解。为方便理解、简化过程,我们假设处理器以 4 字节对齐,通过各平面 Width 计算得到的数据长度若满足 4 的倍数,即可作为各平面的 Stride,无需考虑 Padding 填充。
关于这三种 YUV 格式的采样&存储原理,大家可详细参考上一篇推文 色彩和色彩空间-中篇,下面用到时仅做简述。
由于 I422、 I420 和 NV21 的 Y 平面采样逻辑相同,Y分量均为全采样,我们先统一进行计算。
对于 Y 平面,因为 Y 分量为全采样,故:
- Width_Y_Plane = 每行 Y 分量个数 = 图像每行像素个数 = Width = 720
- Stride_Y_Plane = Width_Y_Plane x 通道位深 = Width_Y_Plane x 8 bit = 720 byte
注:因为 Width_Y_Plane x 8 bit = 720 byte 满足预设的对齐要求,故直接作为 Stride_Y_Plane,实际应用中,需要另外进行确认。后面若有类似处理,不再重复说明。
对于 U、V 平面, 因为 U、V 分量在不同 YUV 格式下有不同的采样、存储逻辑,需要按规则具体计算。
3.1 I422
I422 的采样和存储逻辑简述为:
- 采样:Y 分量全采集,宽度方向每两个 Y 分量共用一组 UV 分量,高度方向每行独立采集 UV 分量
- 存储:Y、U、V 分别存储于三个平面,对于一个宽度为 4 个像素、高度为 2 个像素的采样区域,三个平面分别为 4×2、2×2、2×2 的数组
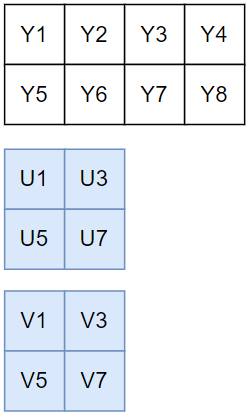
对于 U 平面, U 分量水平方向的采样为 Y 分量的 1/2,故:
- Width_U_Plane = 每行 U 分量个数 = 每行像素个数/2 = Width/2 = 360
- Stride_U_Plane = Width_U_Plane x 通道位深 = 360 byte
对于 V 平面,其采样存储逻辑与 U 平面一致,故:
- Stride_V_Plane = Width_V_Plane x 通道位深 = 360 byte。
如果使用数组 Stride_I422[3] 记录三个平面的跨距(字节长度),即有 Stride_I422[3] = { Width, Width/2, Width/2}(使用 Width 的数值大小来表示)
3.2 I420
I420 的采样和存储逻辑简述为:
- 采样:Y分量全采集,宽度方向和高度方向每四个 Y 分量共用一组 UV 分量,也即第二行复用第一行的 UV 采样;
- 存储:Y、U、V 分别存储于三个平面,对于一个宽度为 4 个像素、高度为 2 个像素的采样区域,三个平面分别为 4×2、2×1、2×1 的数组。

对于 U 平面,U 分量水平方向的采样为 Y 分量的 1/2(每行),故:
- Width_U_Plane = 每行 U 分量个数 = 每行像素个数/2 = Width/2 = 360
- Stride_U_Plane = Width_U_Plane x 通道位深 = 360byte
对于 V 平面,其采样存储逻辑与 U 平面一致,故:
- Stride_V_Plane = Width_V_Plane x 通道位深 = 360byte
如果使用数组 Stride_I420[3] 记录三个平面的跨距(字节长度),即为 Stride_I420[3] = { Width, Width/2, Width/2 }
3.3 NV21
NV21 的采样和存储逻辑简述为:
- 采样:Y分量全采集,宽度方向和高度方向每四个 Y 分量共用一组UV分量,也即第二行复用第一行的 UV 采样
- 存储:Y、UV 分别存储于两个平面,对于一个宽度为 4 个像素、高度为 2 个像素的采样区域,两个平面分别为 4×2、4×1 的数组,UV 共同存储于第二个平面,并按 V、U 的顺序交错存放
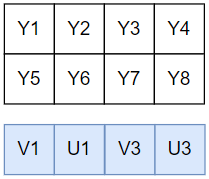
对于 UV 平面,因为 U 、V 水平方向采样均为 Y 分量的1/2(每行) ,并且连续交错存储,故:
- Width_UV_Plane = 每行 U分量个数 + V 分量个数 = 每行像素个数/2 + 每行像素个数/2 = Width = 720
- Stride_UV_Plane = Width_UV_Plane x 通道位深 = 720 byte
如果使用数组 Stride_NV21[2] 记录两个平面的跨距(字节长度),即为 Stride_NV21[2] = { Width, Width }
需要特别注意的是,虽然综合所有平面来说,I422、I420、NV21 每次读取的 Stride 总和,均为 Width x 2 :
- Stride_I422[0] + Stride_I422[1] + Stride_I422[2] = Width x 2
- Stride_I420[0] + Stride_I420[1] + Stride_I420[2] = Width x 2
- Stride_NV21[0] + Stride_NV21[1] = Width x 2
但对于 I420 和 NV21,因其 “宽度方向和高度方向每四个 Y 分量,共用一组UV分量” 的特性,每次读取 U、V 平面、或 UV 平面的一行数据,实际是供 Y 平面的两行数据共用的。因此,平均下来,读取整张图像的数据总量会存在差异:
- Data_I422 = Data_Y + Data_U + Data_V
= Height x Width + Height x Width/2 + Height x Width/2
= Height x Width x 2
- Data_I420 = Data_Y + Data_U + Data_V
= Height x Width + Height/2 x Width/2 + Height/2 x Width/2
= Height x Width x 1.5
- Data_NV21 = Data_Y + Data_UV
= Height x Width + Height/2 x Width
= Height x Width x 1.5
可以看到,Data_I422 大于其余两个。这也证明了 ,YUV420 相对于 YUV422,前者采样数据量更小、压缩率更大。
总结
以上,即为常见 YUV 格式 Width 、 Stride 的计算方法。如果大家在理解上有些难度,可以再回顾一下 色彩和色彩空间-中篇 的内容,结合进行梳理。需要再次强调的是,为方便理解,上面的讲述中默认: 使用 Width 直接计算得到的 Stride 符合对齐要求,无需考虑 Padding 填充,而实践中考虑到不同系统、硬件芯片的对齐处理差异,真实的 Stride 是否要做补齐,仍需再具体确认。
至此,关于计算机如何正确地 、“定量” 读取视频图像数据,我们也有了一定的了解。考虑到硬件芯片、操作系统的多样性,色彩空间采样&存储格式的多样性,要完全厘清所有的 “定量” 规则,还是比较麻烦的。
对于集成 ZEGO SDK 开发音视频应用的同学,ZEGO 音视频引擎已适配了主流的平台和系统,大家可放心地将视频图像的采集、处理、转换、渲染工作交给 SDK,从这些繁琐的细节中解放出来、专注于业务玩法的设计与实现。当然,考虑到灵活性,ZEGO SDK 也提供了 “自定义视频采集” 的功能,允许开发者自行采集、处理原始视图数据,以满足特定的采集源(比如屏幕采集)或者做进阶的视频前处理(比如美颜特效)需求。开发者只需要将采集、处理后的数据,通过指定接口塞给 SDK 即可。
不过,在使用 “自定义视频采集” 功能时,前面提及的色彩空间、采样&存储格式、Width 和 Stride 等概念,就需要你了然于胸,否则就可能出现诸如“斜条纹”的问题。
原创文章,作者:ZEGO即构科技,如若转载,请注明出处:https://market-blogs.zego.im/reports-technique/604/